[TOC]
「Paper Read」MobileNetV1
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
原文地址:MobileNetV1
Abstract
MobileNets是为移动和嵌入式设备提出的高效模型。MobileNets基于流线型架构(streamlined),使用深度可分离卷积(depthwise separable convolutions,即Xception变体结构)来构建轻量级深度神经网络。
论文介绍了两个简单的全局超参数,可有效的在延迟和准确率之间做折中。这些超参数允许我们依据约束条件选择合适大小的模型。论文测试在多个参数量下做了广泛的实验,并在ImageNet分类任务上与其他先进模型做了对比,显示了强大的性能。论文验证了模型在其他领域(对象检测,人脸识别,大规模地理定位等)使用的有效性。
Introduction
深度卷积神经网络将多个计算机视觉任务性能提升到了一个新高度,总体的趋势是为了达到更高的准确性构建了更深更复杂的网络,但是这些网络在尺度和速度上不一定满足移动设备要求。MobileNet描述了一个高效的网络架构,允许通过两个超参数直接构建非常小、低延迟、易满足嵌入式设备要求的模型。
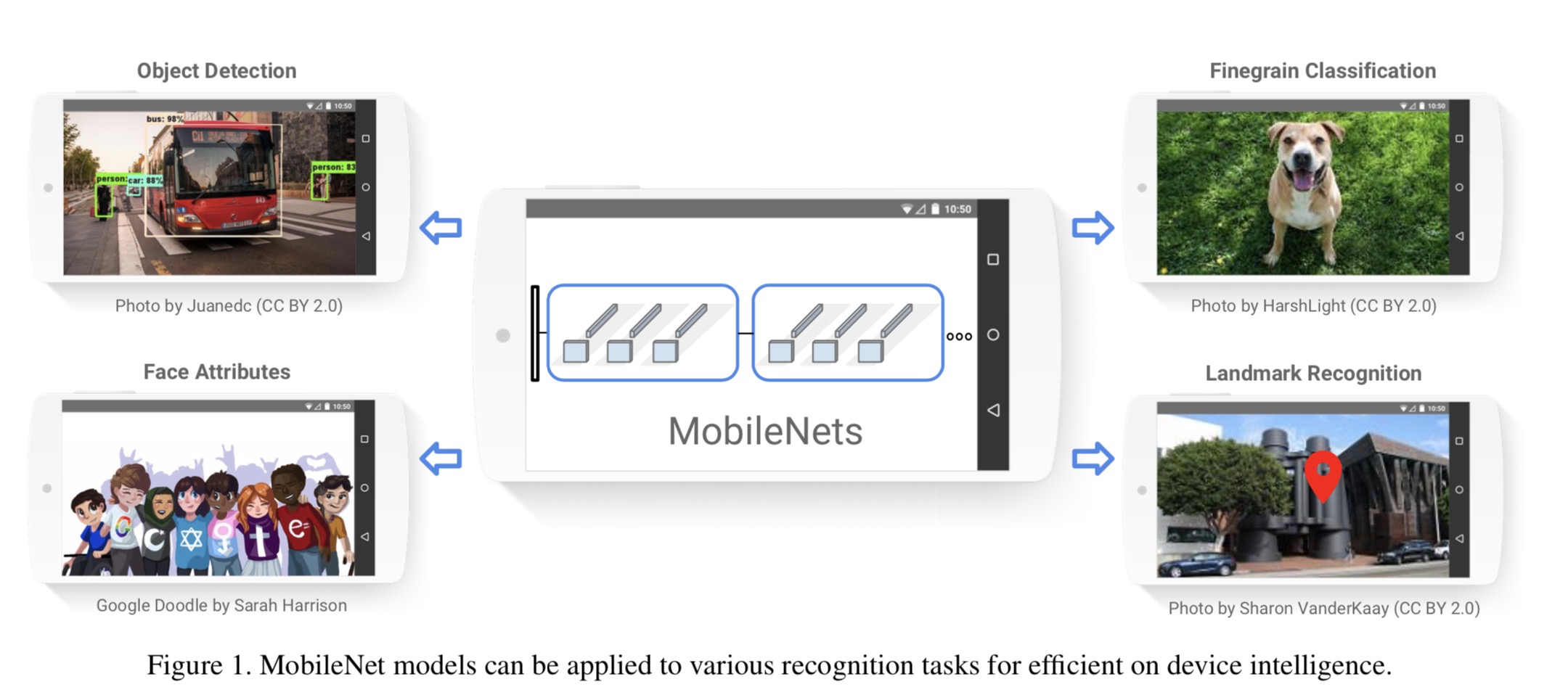
Related Work
现阶段,在建立小型高效的神经网络工作中,通常可分为两类工作:
直接训练小型模型。 例如Flattened networks利用完全的因式分解的卷积网络构建模型,显示出完全分解网络的潜力;Factorized Networks引入了类似的分解卷积以及拓扑连接的使用;Xception network显示了如何扩展深度可分离卷积到Inception V3 networks;Squeezenet 使用一个bottleneck用于构建小型网络。
压缩预训练模型。获得小型网络的一个办法是减小、分解或压缩预训练网络,例如量化压缩(product quantization)、哈希(hashing )、剪枝(pruning)、矢量编码( vector quantization)和霍夫曼编码(Huffman coding)等;此外还有各种分解因子(various factorizations )用来加速预训练网络;还有一种训练小型网络的方法叫蒸馏(distillation ),使用大型网络指导小型网络,这是对论文的方法做了一个补充,后续有介绍补充。
本文提出的MobileNet网络架构,允许模型开发人员专门选择与其资源限制(延迟、大小)匹配的小型模型,MobileNets主要注重于优化延迟同时考虑小型网络,从深度可分离卷积的角度重新构建模型。
Architecture
Depthwise Separable Convolution
MobileNet是基于深度可分离卷积的。通俗的来说,深度可分离卷积干的活是:把标准卷积分解成深度卷积(depthwise convolution)和逐点卷积(pointwise convolution)。这么做的好处是可以大幅度降低参数量和计算量。

设输入的特征映射\(F\)的尺寸为\(\left(D_{F}, D_{F}, M\right)\),输出为\(\left(D_{G}, D_{G}, N\right)\)。
-
标准卷积\(K\)为\(\left(D_{K}, D_{K}, M, N\right)\)
标准卷积的计算公式: \(\mathbf{G}_{k, l, n}=\sum_{i, j, m} \mathbf{K}_{i, j, m, n} \cdot \mathbf{F}_{k+i-1, l+j-1, m}\)
对应的计算量为:
FLOTS,包括加法和乘法: \(\left(2 \cdot D_{K} \cdot D_{K} \cdot M-1\right) \cdot N \cdot D_{F} \cdot D_{F}\)
仅计算乘法(如论文中所述): \[D_{K} \cdot D_{K} \cdot M \cdot N \cdot D_{F} \cdot D_{F}\]-
将标准卷积拆分:
- 深度卷积负责滤波作用,尺寸为\(\left(D_{K}, D_{K}, 1, M\right)\),输出为\(\left(D_{G}, D_{G}, M\right)\)。
- 逐点卷积负责转换通道,尺寸为\(\left(1, 1, M, N\right)\),输出为\(\left(D_{G}, D_{G}, N \right)\)。
深度卷积的公式为:
\[\hat{\mathbf{G}}_{k, l, m}=\sum_{i, j} \hat{\mathbf{K}}_{i, j, m} \cdot \mathbf{F}_{k+i-1, l+j-1, m}\]深度卷积和逐点卷积计算量:\(D_K·D_K·M·D_F·D_F + M·N·D_F·D_F\)
计算量减少了:
\[\begin{aligned} & \frac{D_{K} \cdot D_{K} \cdot M \cdot D_{F} \cdot D_{F}+M \cdot N \cdot D_{F} \cdot D_{F}}{D_{K} \cdot D_{K} \cdot M \cdot N \cdot D_{F} \cdot D_{F}} \\=& \frac{1}{N}+\frac{1}{D_{K}^{2}} \end{aligned}\]Remind:
-
Depthwise convolution is extremely efficient relative to standard convolution. However it only filters input chan- nels, it does not combine them to create new features. So an additional layer that computes a linear combination of the output of depthwise convolution via 1 × 1 convolution is needed in order to generate these new features.
-
MobileNet uses 3 × 3 depthwise separable convolutions which uses between 8 to 9 times less computation than stan- dard convolutions at only a small reduction in accuracy
计算说明:
1、标准卷积核是,s * s * m 与 f * f * m 得到一个 g * g * 1的输出,把每个通道的输出累加。
2、深度卷积核是,s * s * m 与 m 个 f * f * 1得到一个g * g * m的输出,每一个通道是一一对应直接出来结果,然后再融合在一起。
Network Structure and Training
标准卷积和MobileNet中使用的深度分离卷积结构对比如下:
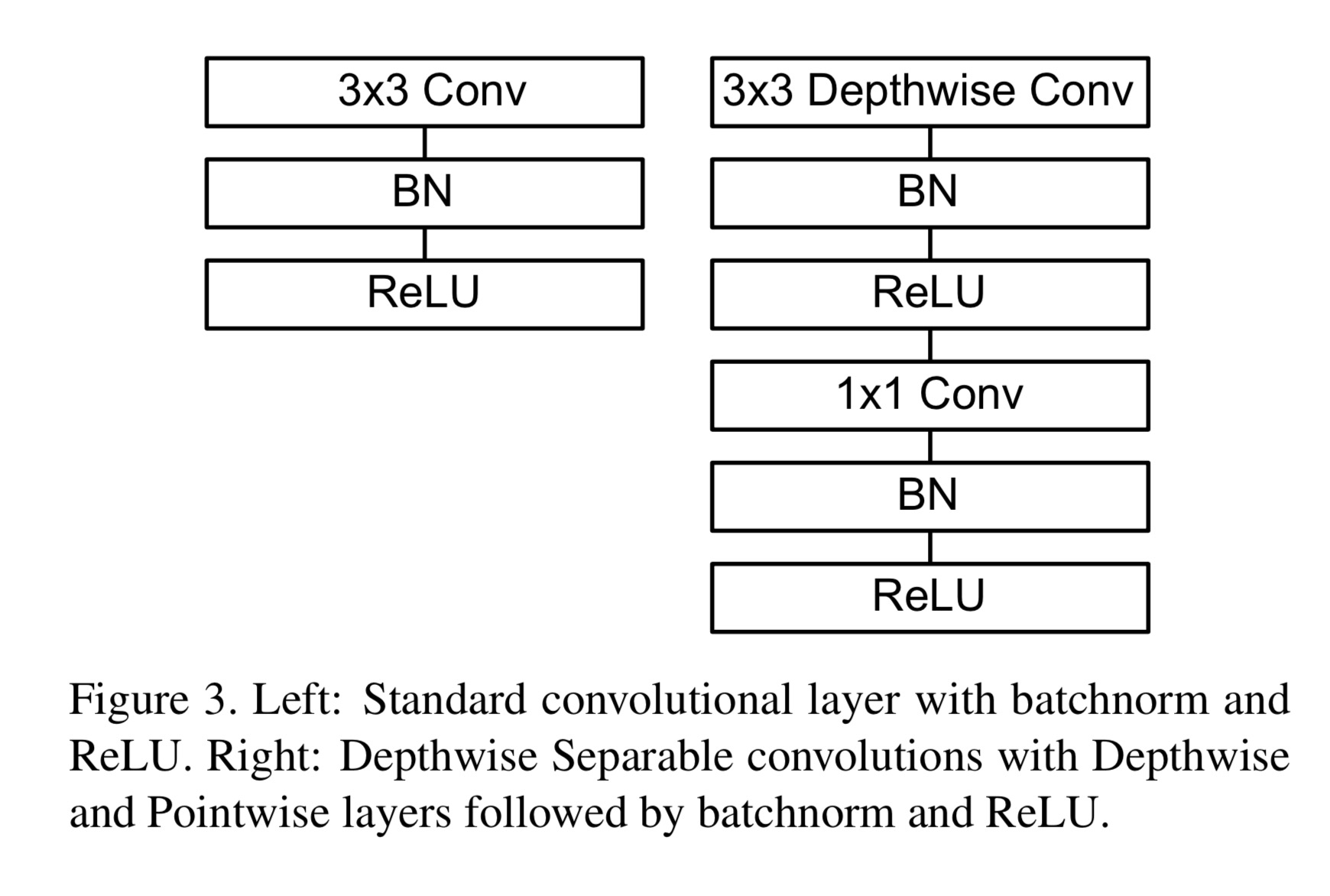
除了最后的FC层没有非线性激活函数,其他层都有BN和ReLU非线性函数。
如果是需要下采样,则在第一个深度卷积上取stide = 2。
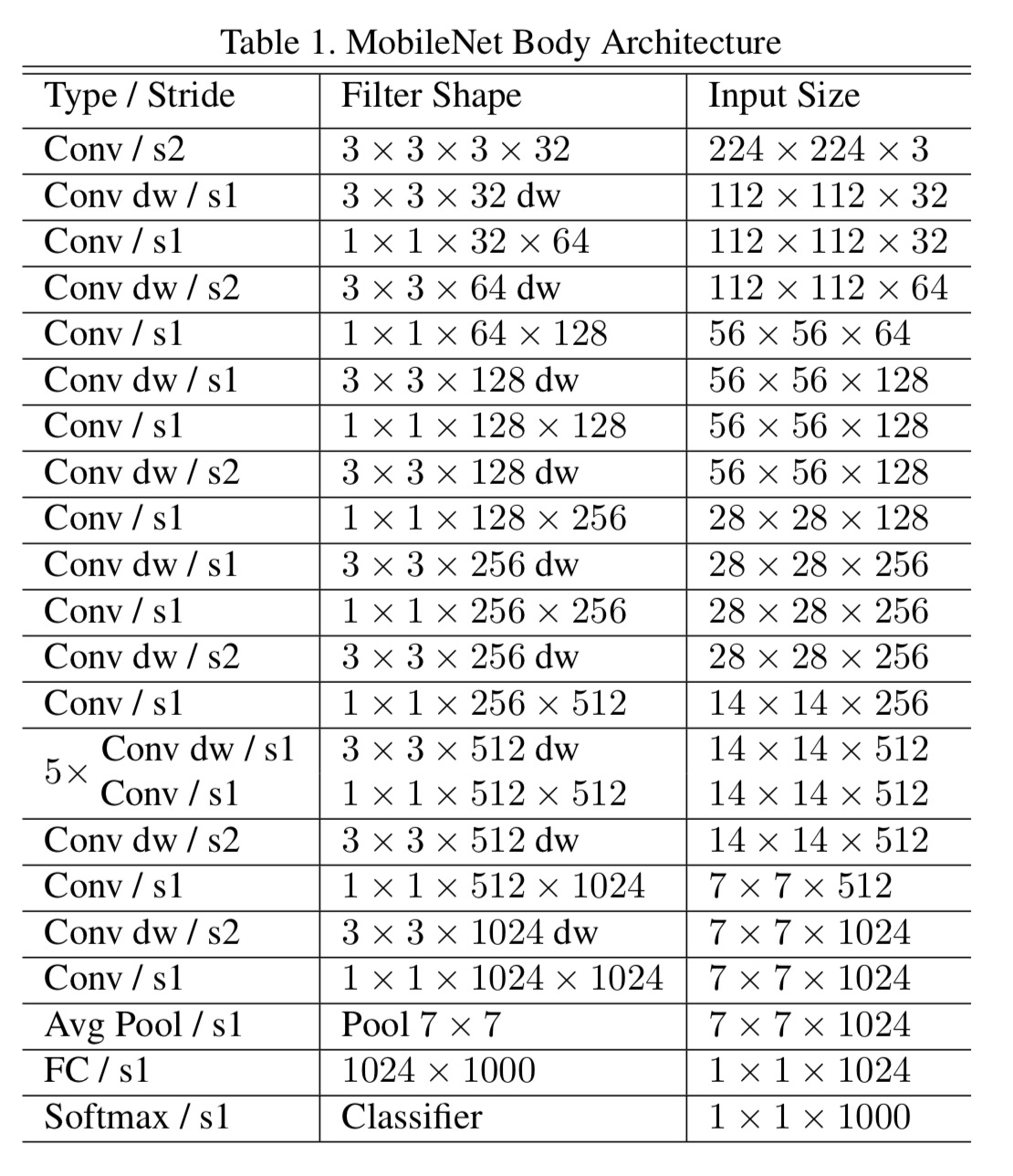
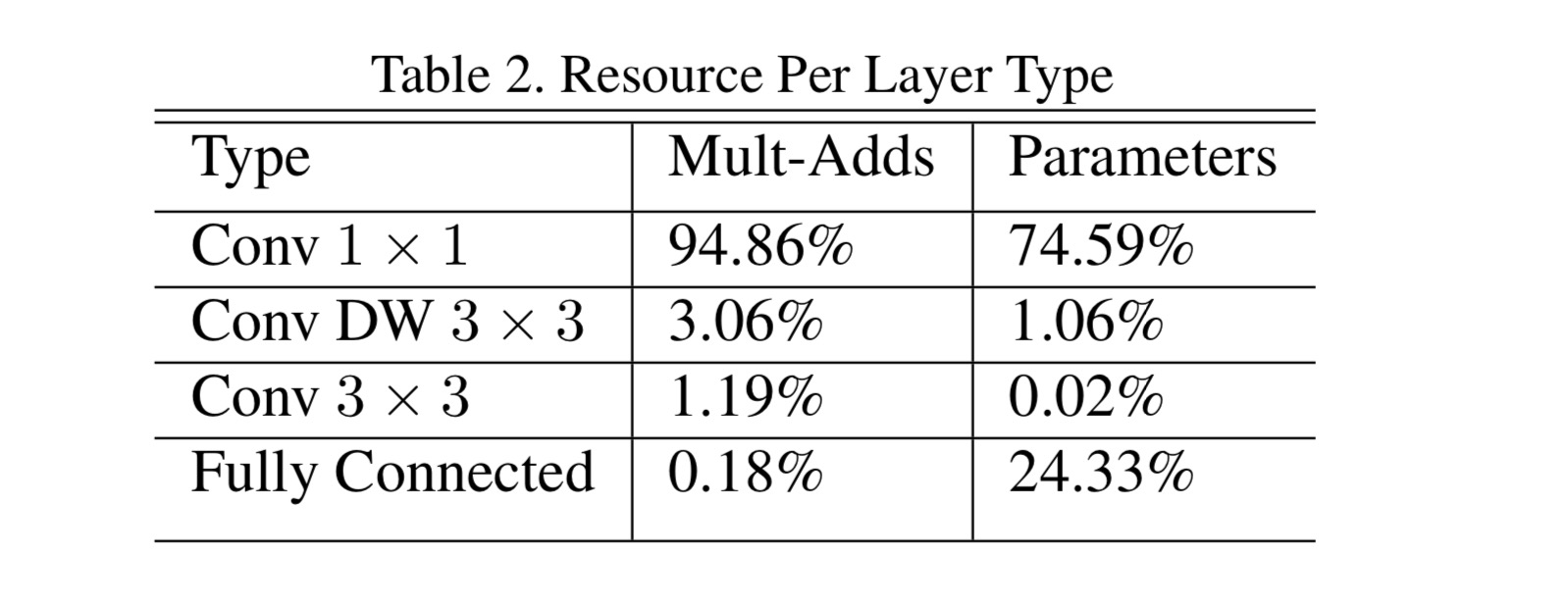
我们的模型几乎将所有的密集运算放到1×1卷积上,这可以使用general matrix multiply (GEMM) functions优化。在MobileNet中有95%的时间花费在1×1卷积上,这部分也占了75%的参数,其它参数基本都在全连接层上:
在TensorFlow中使用RMSprop对MobileNet做训练,使用类似InceptionV3 的异步梯度下降。与训练大型模型不同的是,我们较少使用正则和数据增强技术,因为小模型不易陷入过拟合;没有使用side heads or label smoothing,我们发现在深度卷积核上放入很少的L2正则或不设置权重衰减的很重要,因为这部分参数很少。
Width Multiplier: Thinner Models
我们引入的第一个控制模型大小的超参数是:宽度因子\(\alpha\)(Width multiplier ),用于控制输入和输出的通道数,即输入通道从\(M\)变为\(\alpha M\),输出通道从\(N\)变为\(\alpha N\)。
深度卷积和逐点卷积的计算量:
\[D_{K} \cdot D_{K} \cdot \alpha M \cdot D_{F} \cdot D_{F}+\alpha M \cdot \alpha N \cdot D_{F} \cdot D_{F}\]可设置\(\alpha \in(0,1]\),通常取1,0.75,0.5和0.25。
计算量减少了:
\[\frac{D_{K} \cdot D_{K} \cdot \alpha M \cdot D_{F} \cdot D_{F}+\alpha M \cdot \alpha N \cdot D_{F} \cdot D_{F}}{D_{K} \cdot D_{K} \cdot M \cdot N \cdot D_{F} \cdot D_{F}}=\frac{\alpha}{N}+\frac{\alpha^{2}}{D_{K}^{2}}\]宽度因子将计算量和参数降低了约\(\alpha^2\)倍,可很方便的控制模型大小。
Resolution Multiplier: Reduced Representation
我们引入的第二个控制模型大小的超参数是:分辨率因子 \(\rho\)(resolution multiplier )。用于控制输入和内部层表示。即用分辨率因子控制输入的分辨率。
深度卷积和逐点卷积的计算量:
\[D_{K} \cdot D_{K} \cdot \alpha M \cdot \rho D_{F} \cdot \rho D_{F}+\alpha M \cdot \alpha N \cdot \rho D_{F} \cdot \rho D_{F}\]可设置\(\rho \in(0,1]\),通常设置输入分辨率为224,192,160和128。
计算量减少了:
\[\frac{D_{K} \cdot D_{K} \cdot \alpha M \cdot \rho D_{F} \cdot \rho D_{F}+\alpha M \cdot \alpha N \cdot \rho D_{F} \cdot \rho D_{F}}{D_{K} \cdot D_{K} \cdot M \cdot N \cdot D_{F} \cdot D_{F}}=\frac{\alpha \rho}{N}+\frac{\alpha^{2} \rho^{2}}{D_{K}^{2}}\] \[\frac{D_{K} \cdot D_{K} \cdot \alpha M \cdot \rho D_{F} \cdot \rho D_{F}+\alpha M \cdot \alpha N \cdot \rho D_{F} \cdot \rho D_{F}}{D_{K} \cdot D_{K} \cdot M \cdot N \cdot D_{F} \cdot D_{F}}=\frac{\alpha}{N}+\frac{\alpha^{2}}{D_{K}^{2}}\]宽度因子将计算量和参数降低了约\(\rho^2\)倍,可很方便的控制模型大小。
下面的示例展现了宽度因子和分辨率因子对模型的影响:
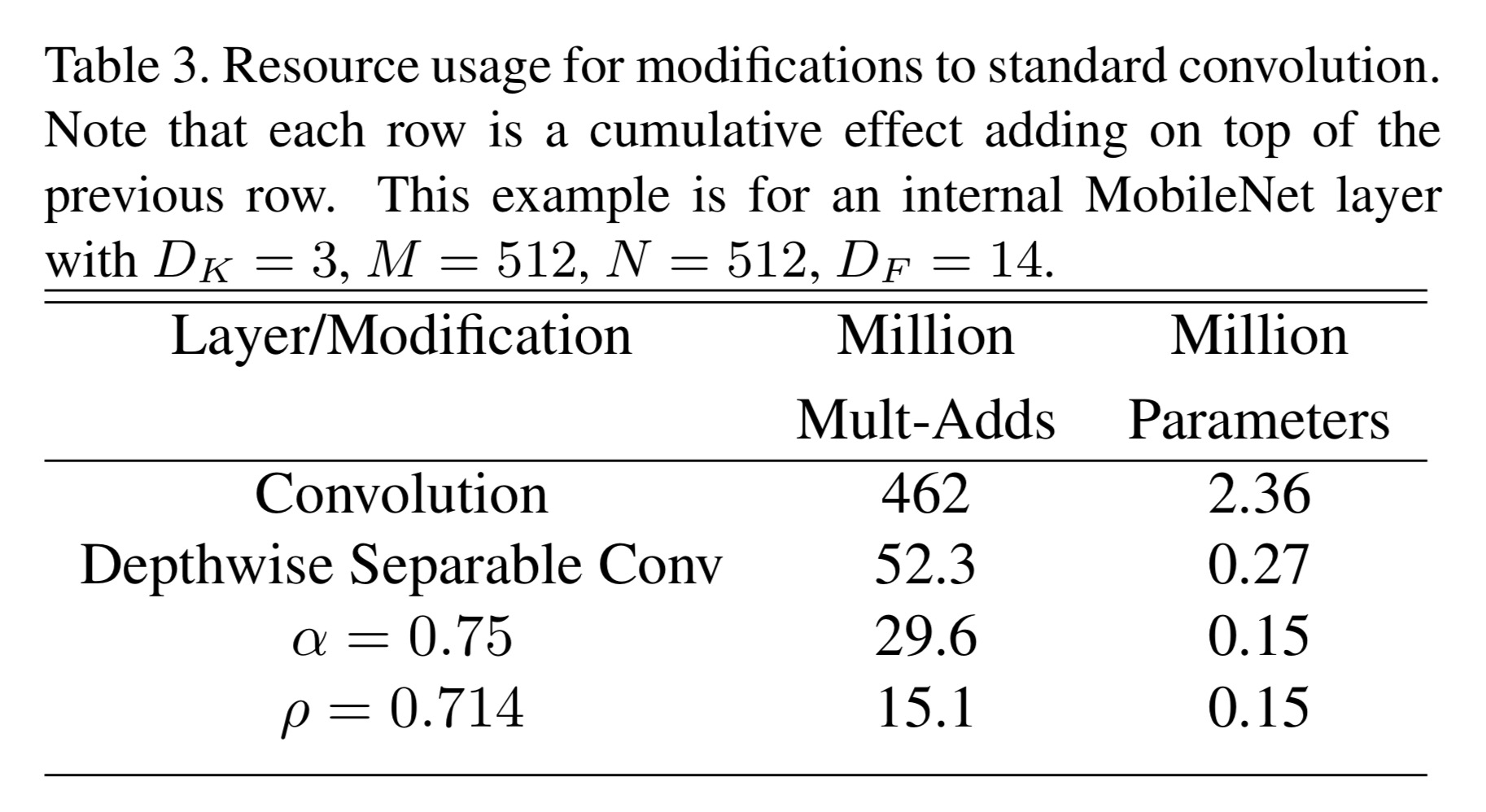
Experiment
可见参考资料1。
参考:
1、https://blog.csdn.net/u011974639/article/details/79199306
2、https://zhuanlan.zhihu.com/p/33634489
3、[Flops]](https://link.zhihu.com/?target=https%3A//stats.stackexchange.com/questions/291843/how-to-understand-calculate-flops-of-the-neural-network-model)