目标定位
目标检测模型框架
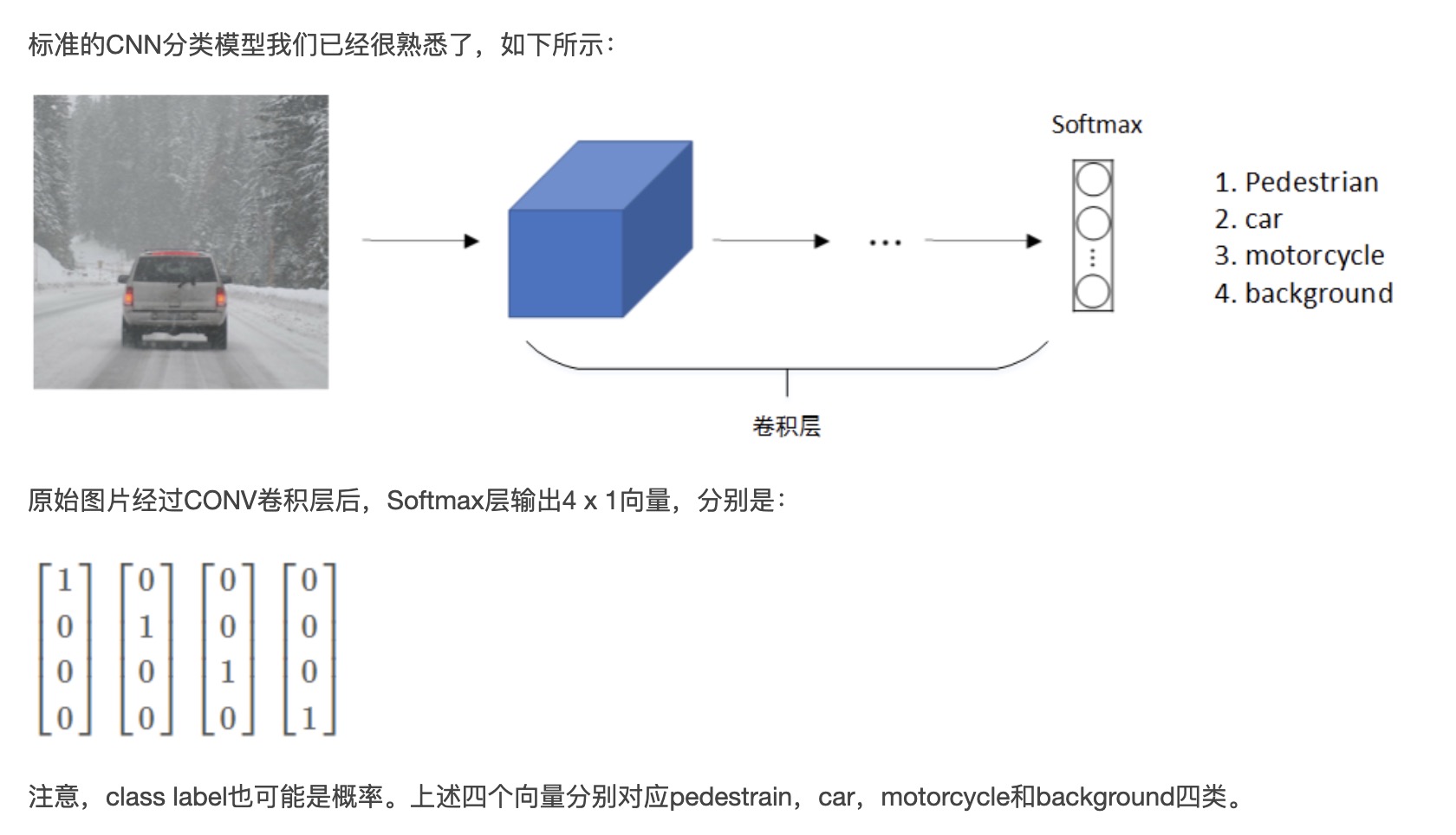
第一个组件表示\(p_c\)是否含有对象
- 如果对象属于前三类(行人、汽车、摩托车),则\(p_c = 1\)。
- 如果是背景,则图片中没有要检测的对象,则\(p_c = 0\)。
如果检测到对象,即\(p_c = 1\),就输出被检测对象的边界框参数b和类别参数c。
损失函数

特征点检测
除了使用矩形区域检测目标类别和位置外,我们还可以仅对目标的关键特征点坐标进行定位,这些关键点被称为landmarks。
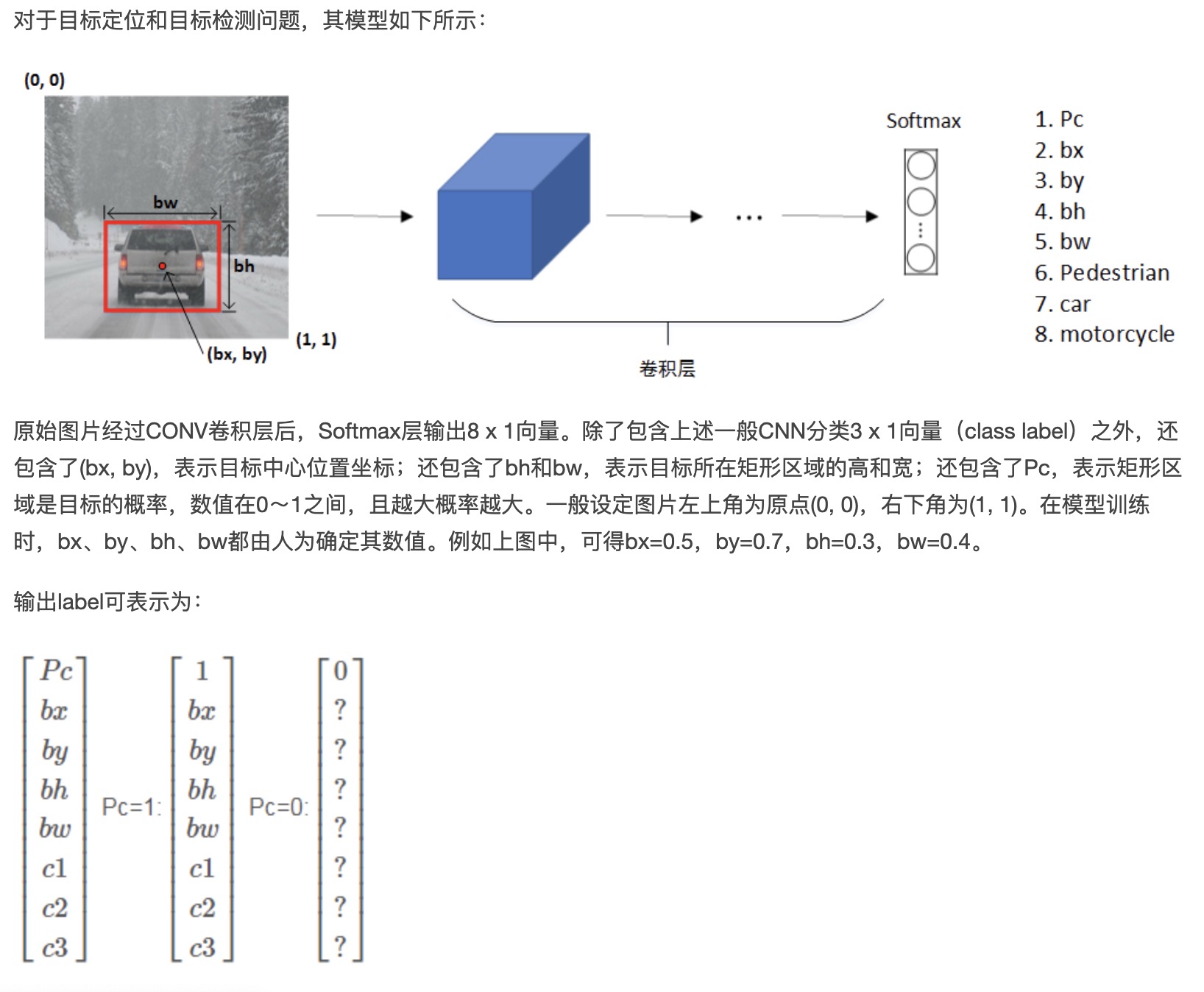
例如人脸识别,可以对人脸部分特征点坐标进行定位检测,并标记出来,如下图所示:

该网络模型共检测人脸上64处特征点,加上是否为face的标志位,输出label共有64×2+1=129个值。通过检测人脸特征点可以进行情绪分类与判断,或者应用于AR领域等等。
除了人脸特征点检测之外,还可以检测人体姿势动作,如下图所示:
目标检测-sliding window
目标检测的一种简单方法是滑动窗算法。这种算法首先在训练样本集上搜集相应的各种目标图片和非目标图片。注意训练集图片尺寸较小,尽量仅包含相应目标,如下图所示:

然后,使用这些训练集构建CNN模型,使得模型有较高的识别率。
最后,在测试图片上,选择大小适宜的窗口、合适的步进长度,进行从左到右、从上倒下的滑动。每个窗口区域都送入之前构建好的CNN模型进行识别判断。若判断有目标,则此窗口即为目标区域;若判断没有目标,则此窗口为非目标区域。

优点:
- 原理简单,且不需要人为选定目标区域(检测出目标的滑动窗即为目标区域)。
缺点:
- 滑动窗的大小和步进长度都需要人为直观设定
- 滑动窗过小或过大,步进长度过大均会降低目标检测正确率
- 每次滑动窗区域都要进行一次CNN网络计算
- 性能不佳,不够快,不够灵活
卷积方法实现Sliding Window
滑动窗算法可以使用卷积方式实现,以提高运行速度,节约重复运算成本。
首先,单个滑动窗口区域进入CNN网络模型时,包含全连接层。那么滑动窗口算法卷积实现的第一步就是将全连接层转变成为卷积层,如下图所示:
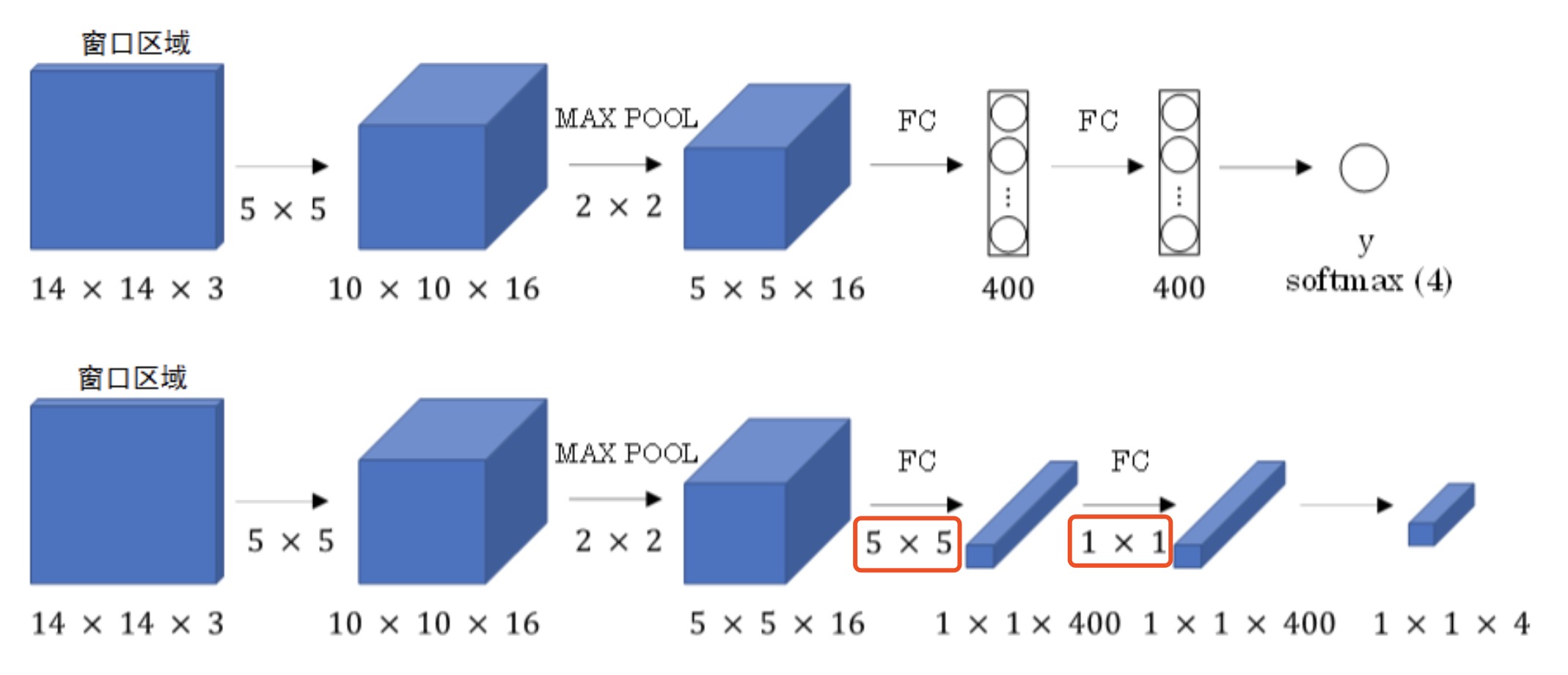
全连接层转变成卷积层的操作很简单,只需要使用与上层尺寸一致的滤波算子进行卷积运算(如上图红框处所示)即可。最终得到的输出层维度是1 x 1 x 4,代表4类输出值。
单个窗口区域卷积网络结构建立完毕之后,对于待检测图片,即可使用该网络参数和结构进行运算。例如16 x 16 x 3的图片,步进长度为2,CNN网络得到的输出层为2 x 2 x 4。其中,2 x 2表示共有4个窗口结果。对于更复杂的28 x 28 x3的图片,CNN网络得到的输出层为8 x 8 x 4,共64个窗口结果。

之前的滑动窗算法需要反复进行CNN正向计算,例如16 x 16 x 3的图片需进行4次,28 x 28 x3的图片需进行64次。而利用卷积操作代替滑动窗算法,则不管原始图片有多大,只需要进行一次CNN正向计算,因为其中共享了很多重复计算部分,这大大节约了运算成本。
窗口步进长度与选择的MAX POOL大小有关。如果需要步进长度为4,只需设置MAX POOL为4 x 4即可。
BBox 准确预测
滑动窗口法中,都是离散的位置集合,在它们上运行分类器,在这种情况下,大部分时候,这些边界框没有一个能完美匹配汽车位置,如下图蓝色窗口所示:

其中一个能得到更精准边界框的算法是YOLO算法。
利用上一节卷积形式实现滑动窗口算法的思想,对该原始图片构建CNN网络,得到的的输出层维度为3 x 3 x 8。其中,3 x 3对应9个网格,每个网格的输出包含8个元素:
\[y=\left[\begin{array}{l}{p_{c}} \\ {b_{x}} \\ {b_{y}} \\ {b_{h}} \\ {b_{w}} \\ {c_{1}} \\ {c_{2}} \\ {c_{3}}\end{array}\right]\]

Yolo算法通过卷积操作,最后输出预测值。
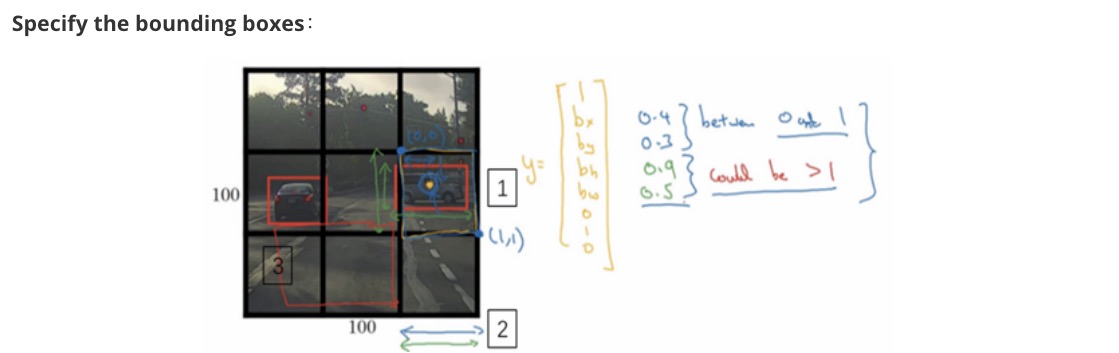
IoU
IoU,即交集与并集之比,可以用来评价目标检测区域的准确性。

如上图所示,红色方框为真实目标区域,蓝色方框为检测目标区域。两块区域的交集为绿色部分,并集为紫色部分。蓝色方框与红色方框的接近程度可以用IoU比值来定义:
\[I o U=\frac{I}{U}\]IoU可以表示任意两块区域的接近程度。IoU值介于0~1之间,且越接近1表示两块区域越接近。
一般约定,在计算机检测任务中,如果iou大于等于0.5,就说检测正确。这个阈值可以人为设定。
NMS
有可能存在对同一个对象做出多次检测,非极大抑制方法确保对每个对象只检测一次。

上图中,三个绿色网格和三个红色网格分别检测的都是同一目标。那如何判断哪个网格最为准确呢?方法是使用非最大值抑制算法。
非最大值抑制(Non-max Suppression)做法很简单,图示每个网格的Pc值可以求出,Pc值反映了该网格包含目标中心坐标的可信度。首先选取Pc最大值对应的网格和区域,然后计算该区域与所有其它区域的IoU,剔除掉IoU大于阈值(例如0.5)的所有网格及区域。这样就能保证同一目标只有一个网格与之对应,且该网格Pc最大,最可信。接着,再从剩下的网格中选取Pc最大的网格,重复上一步的操作。最后,就能使得每个目标都仅由一个网格和区域对应。如下图所示:
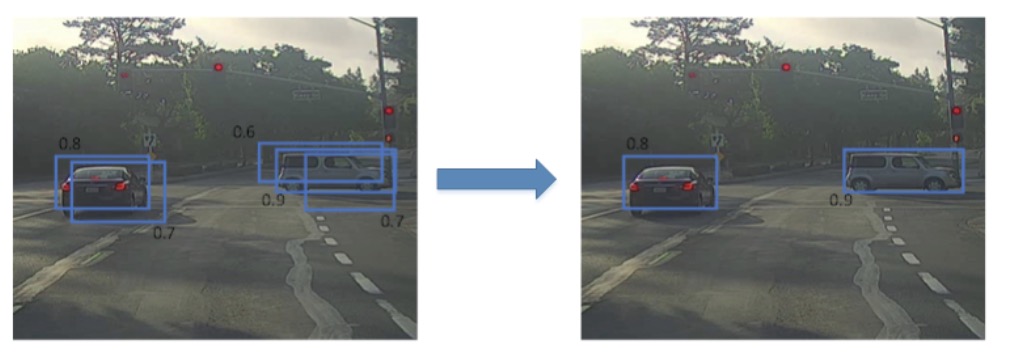
总结一下非最大值抑制算法的流程:
-
剔除Pc值小于某阈值(例如0.6)的所有网格;
-
选取Pc值最大的网格,利用IoU,摒弃与该网格交叠较大的网格;
-
对剩下的网格,重复步骤2。
Anchor Boxes
到目前为止,对象检测中存在的一个问题是每个格子只能检测出一个对象,如果想让一个格子检测出多个对象,就要使用anchor box这个概念。
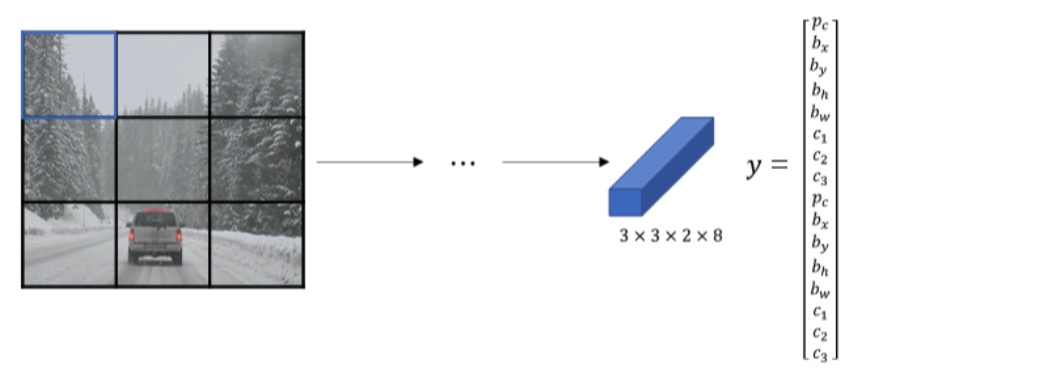
如下图所示,同一网格出现了两个目标:人和车。为了同时检测两个目标,我们可以设置两个Anchor Boxes,Anchor box 1检测人,Anchor box 2检测车。也就是说,每个网格多加了一层输出。原来的输出维度是 3 x 3 x 8,现在是3 x 3 x 2 x 8(也可以写成3 x 3 x 16的形式)。这里的2表示有两个Anchor Boxes,用来在一个网格中同时检测多个目标。每个Anchor box都有一个Pc值,若两个Pc值均大于某阈值,则检测到了两个目标。
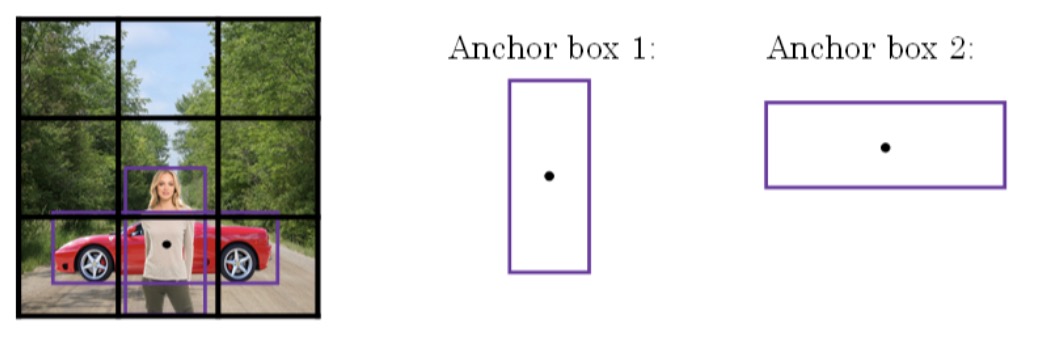
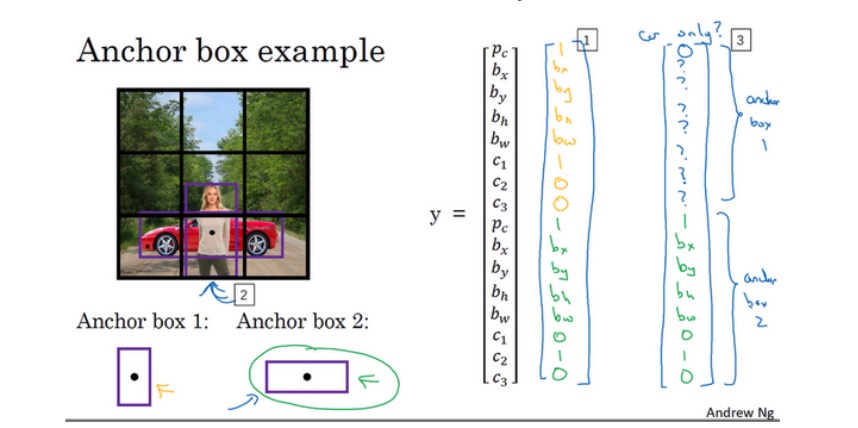
如果一个cell里的行人更像anchor box 1,则把它分配到向量的上半部分,如果更像anchor box 2,则把它分配到向量的下半部分。
如果一个cell里只有一个目标且那个目标更像某个anchor box,则该anchor box里储存该物体的信息,另外一个anchor box为空。
如果你有两个anchor box,但在同一个格子中有三个对象,这种情况算法处理不好。
在使用YOLO算法时,只需对每个Anchor box使用上一节的非最大值抑制即可。Anchor Boxes之间并行实现。
并且,Anchor Boxes形状的选择可以通过人为选取,也可以使用其他机器学习算法,例如k聚类算法对待检测的所有目标进行形状分类,选择主要形状作为Anchor Boxes。
YOLO
这一节主要介绍yolo算法流程,介绍的比较粗糙。网络结构如下,包含了两个Anchor Boxes。
- For each grid call, get 2 predicted bounding boxes.
- Get rid of low probability predictions.
- For each class (pedestrian, car, motorcycle) use non-max suppression to generate final predictions.
Region proposals
粗略介绍了一下two-stage的算法。