[TOC]
经典网络
LeNet-5
LeNet-5模型是Yann LeCun教授于1998年提出来的,它是第一个成功应用于数字识别问题的卷积神经网络。在MNIST数据中,它的准确率达到大约99.2%。典型的LeNet-5结构包含CONV layer,POOL layer和FC layer,顺序一般是CONV layer->POOL layer->CONV layer->POOL layer->FC layer->FC layer->OUTPUT layer,即\(\hat y\)。下图所示的是一个数字识别的LeNet-5的模型结构:

该LeNet模型总共包含了大约6万个参数。值得一提的是,当时Yann LeCun提出的LeNet-5模型池化层使用的是average pool,而且各层激活函数一般是Sigmoid和tanh。现在,我们可以根据需要,做出改进,使用max pool和激活函数ReLU。
lenet-5论文重点:
1、使用sigmod函数和tanh函数,而不是ReLu函数。这种网络结构的特别之处还在于,各网络层之间是有关联的。
2、每个过滤器都采用和输入模块一样的通道数量。
3、最难理解的一段:在池化后进行了非线性函数处理,池化层之后使用了sigmod函数。
4、阅读重点第二段,泛读第三段实验结果。
AlexNet
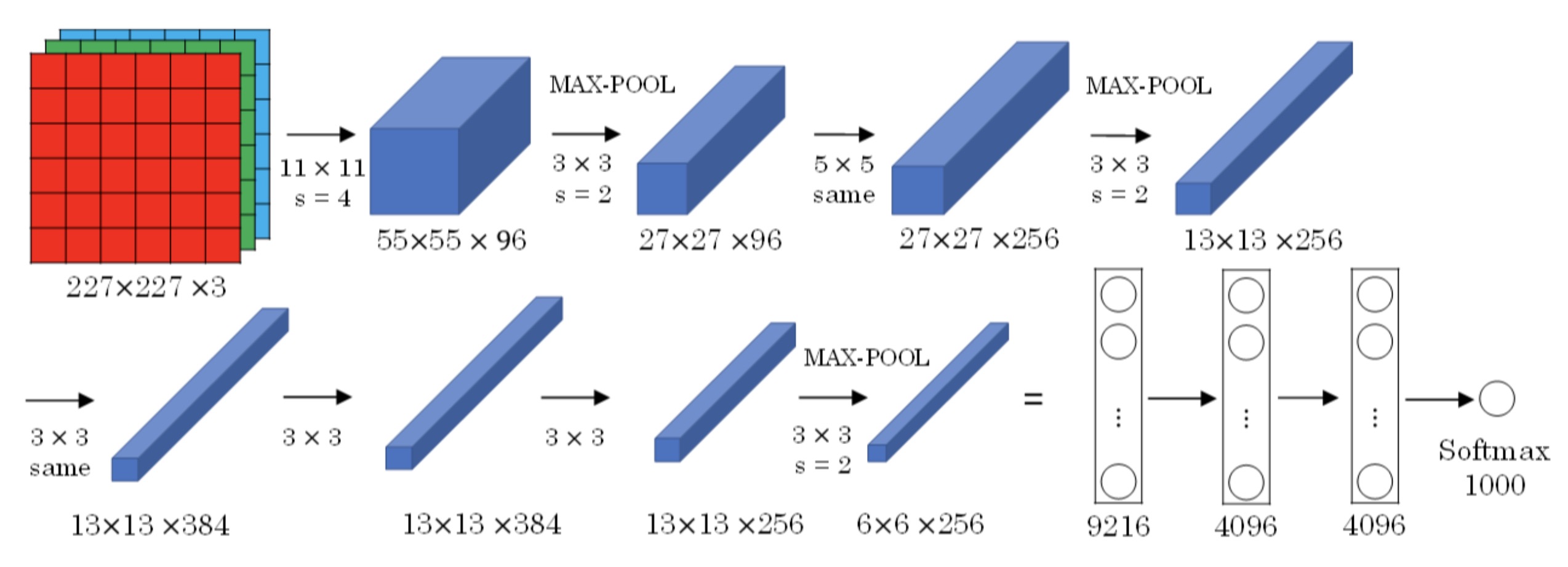
AlexNet模型与LeNet-5模型类似,只是要复杂一些,总共包含了大约6千万个参数。同样可以根据实际情况使用激活函数ReLU。原作者还提到了一种优化技巧,叫做Local Response Normalization(LRN)。 而在实际应用中,LRN的效果并不突出。
当用于训练图像和数据集时,AlexNet能够处理非常相似的基本构造模块,这些模块往往包含着大量的隐藏单元或数据,这一点AlexNet表现出色。AlexNet比LeNet表现更为出色的另一个原因是它使用了ReLu激活函数。
局部响应归一层的基本思路是,假如这是网络的一块,比如是13×13×256,LRN要做的就是选取一个位置,从这个位置穿过整个通道,能得到256个数字,并进行归一化。进行局部响应归一化的动机是,对于这张13×13的图像中的每个位置来说,我们可能并不需要太多的高激活神经元。但是后来,很多研究者发现LRN起不到太大作用,这应该是被我划掉的内容之一,因为并不重要,而且我们现在并不用LRN来训练网络。
VGG-16
VGG-16网络没有那么多超参数,这是一种只需要专注于构建卷积层的简单网络。
-
3×3,步幅为1的过滤器构建卷积层,padding参数为same卷积中的参数。
-
2×2,步幅为2的过滤器构建最大池化层。
因此VGG网络的一大优点是它确实简化了神经网络结构,下面我们具体讲讲这种网络结构。
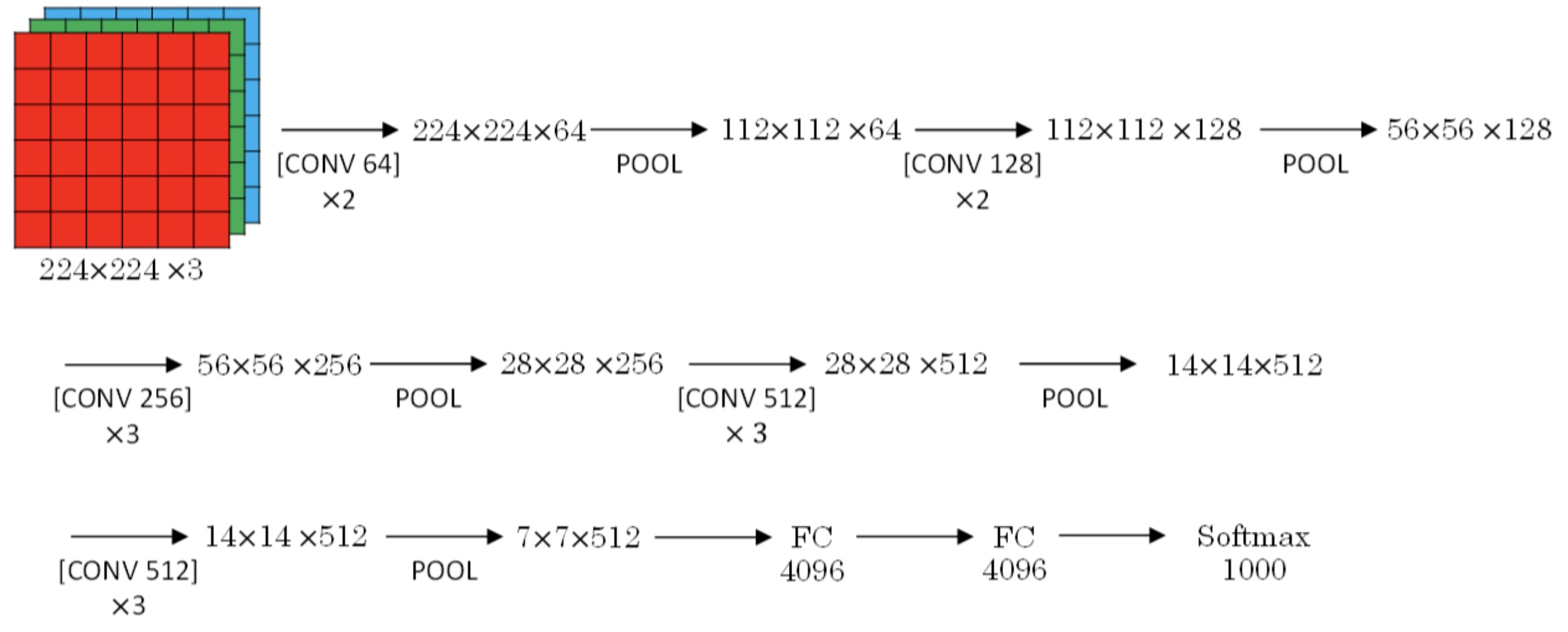
VGG-16包含1.38亿个参数。
优点:相对一致的网络结构
缺点:训练的特征数量非常巨大
文中揭示了,随着网络的加深,图像的高度和宽度都在以一定的规律不断缩小,每次池化后刚好缩小一半,而通道数量在不断增加,而且刚好也是在每组卷积操作后增加一倍。也就是说,图像缩小的比例和通道数增加的比例是有规律的。
从介绍AlexNet的论文开始,然后就是VGG的论文,最后是LeNet的论文。
Resnet
如果神经网络层数越多,网络越深,源于梯度消失和梯度爆炸的影响,整个模型难以训练成功。解决的方法之一是人为地让神经网络某些层跳过下一层神经元的连接,隔层相连,弱化每层之间的强联系。这种神经网络被称为Residual Networks(ResNets)。
跳跃连接(Skip connection),它可以从某一层网络层获取激活,然后迅速反馈给另外一层,甚至是神经网络的更深层。
Residual Networks由许多隔层相连的神经元子模块组成,我们称之为Residual block。单个Residual block的结构如下图所示:
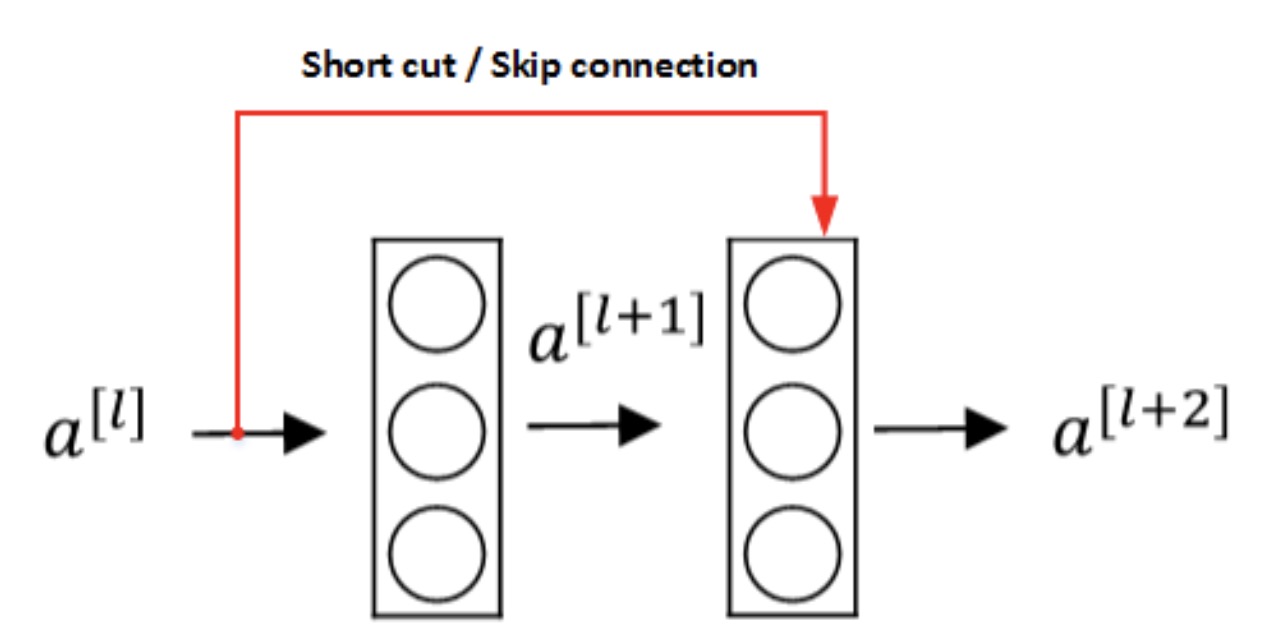
上图中红色部分就是skip connection,直接建立\(a^{[l]}\)与\(a^{[l+2]}\)之间的隔层联系。相应的表达式如下:
\(\begin{aligned} z^{[l+1]} &=W^{[l+1]} a^{[l]}+b^{[l+1]} \\ a^{[l+1]} &=g\left(z^{[l+1]}\right) \\ z^{[l+2]} &=W^{[l+2]} a^{[l+1]}+b^{[l+2]} \\ a^{[l+2]} &=g\left(z^{[l+2]}+a^{[l]}\right) \end{aligned}\) 原本的表达式应该是: \(\begin{aligned} z^{[l+1]} &=W^{[l+1]} a^{[l]}+b^{[l+1]} \\ a^{[l+1]} &=g\left(z^{[l+1]}\right) \\ z^{[l+2]} &=W^{[l+2]} a^{[l+1]}+b^{[l+2]} \\ a^{[l+2]} &=g\left(z^{[l+2]}\right) \end{aligned}\) 所以\(a^{[l]}\)插入的时机是在线性激活之后,ReLU激活之前。
除了捷径,你还会听到另一个术语“跳跃连接”,就是指\(a^{[l]}\)跳过一层或者好几层,从而将信息传递到神经网络的更深层。
为什么Resnet能训练更深层的神经网络?
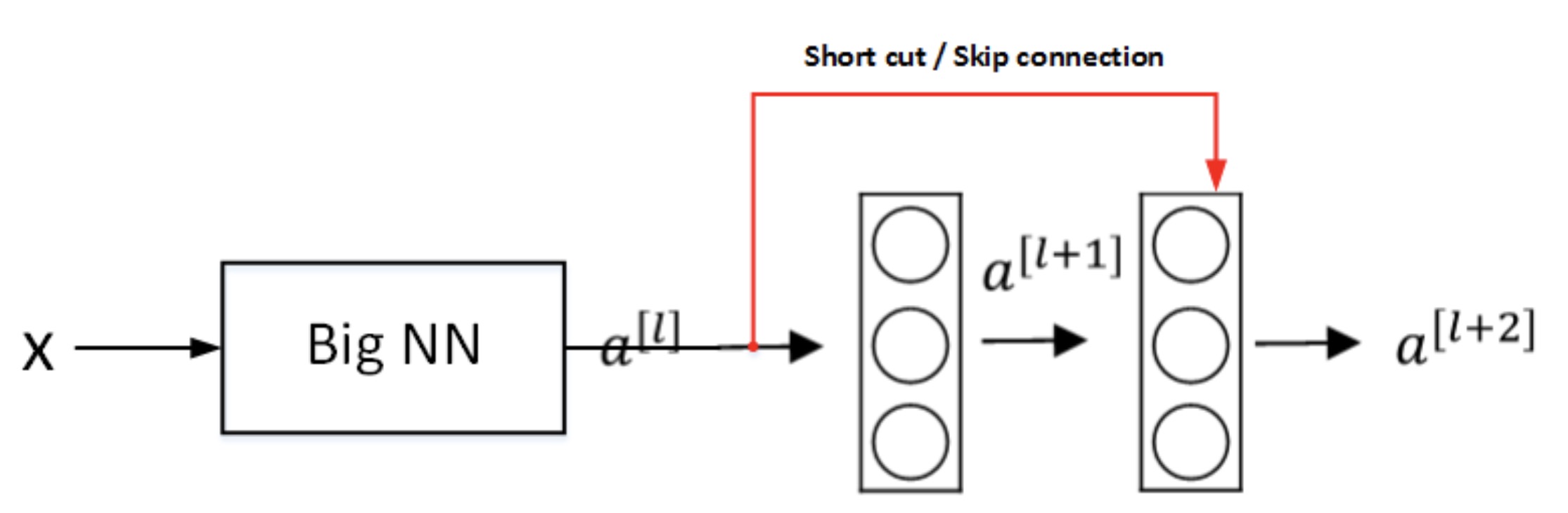
如上图所示,输入x经过很多层神经网络后输出\(a^{[l]}\),\(a^{[l]}\)经过一个Residual block输出\(a^{[l+2]}\)。\(a^{[l+2]}\)的表达式为:
\(a^{[l+2]}=g(z^{[l+2]}+a^{[l]})=g(W^{[l+2]}a^{[l+1]}+b^{[l+2]}+a^{[l]})\) 输入x经过Big NN后,若\(W^{[l+2]}\approx0\),\(b^{[l+2]}\approx0\),则有:
\(a^{[l+2]}=g(a^{[l]})=ReLU(a^{[l]})=a^{[l]}\ \ \ \ when\ a^{[l]}\geq0\) 可以看出,即使发生了梯度消失,\(W^{[l+2]}\approx0\),\(b^{[l+2]}\approx0\),也能直接建立\(a^{[l+2]}\)与\(a^{[l]}\)的线性关系,且\(a^{[l+2]}=a^{[l]}\),这其实就是identity function。\(a^{[l]}\)直接连到\(a^{[l+2]}\),从效果来说,相当于直接忽略了\(a^{[l]}\)之后的这两层神经层。这样,看似很深的神经网络,其实由于许多Residual blocks的存在,弱化削减了某些神经层之间的联系,实现隔层线性传递,而不是一味追求非线性关系,模型本身也就能“容忍”更深层的神经网络了。而且从性能上来说,这两层额外的Residual blocks也不会降低Big NN的性能。
- 如果Residual blocks能训练得到非线性关系,那么也会忽略short cut,跟Plain Network起到同样的效果。
- 当网络不断加深时,就算是选用学习恒等函数的参数都很困难,所以很多层最后的表现不但没有更好,反而更糟。
残差网络起作用的主要原因就是这些残差块学习恒等函数非常容易,你能确定网络性能不会受到影响,很多时候甚至可以提高效率,或者说至少不会降低网络的效率,因此创建类似残差网络可以提升网络性能。
\(z^{[l+2]}\)与\(a^{[l]}\)的维度问题:
- ResNets使用了许多same卷积保留维度,所以\(a^{[l]}\)的维度等于输出层的维度,很容易得出这个捷径连接,并输出这两个相同维度的向量。
- 如果输入输出有不同维度,用参数矩阵。

Network in Network and 1×1 convolutions
1×1的卷积能做什么呢?
过滤器为1×1,这里是数字2,输入一张6×6×1的图片,然后对它做卷积,起过滤器大小为1×1×1,结果相当于把这个图片乘以数字2,所以前三个单元格分别是2、4、6等等。用1×1的过滤器进行卷积,似乎用处不大,只是对输入矩阵乘以某个数字。但这仅仅是对于6×6×1的一个通道图片来说,1×1卷积效果不佳。
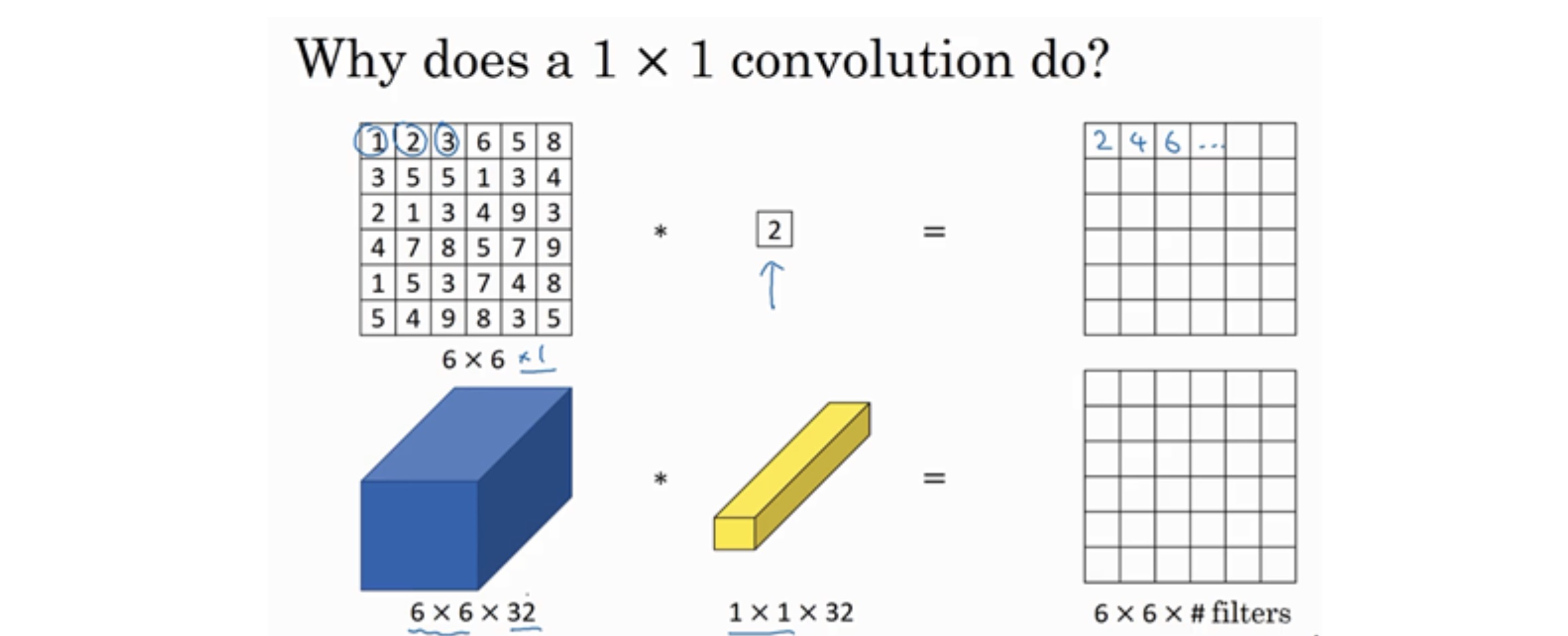
如果是一张6×6×32的图片,那么使用1×1过滤器进行卷积效果更好。具体来说,1×1卷积所实现的功能是遍历这36个单元格,计算左图中32个数字和过滤器中32个数字的元素积之和,然后应用ReLU非线性函数。


我们以其中一个单元为例,它是这个输入层上的某个切片,用这36个数字乘以这个输入层上1×1切片,得到一个实数,像这样把它画在输出中。
这个1×1×32过滤器中的32个数字可以这样理解,一个神经元的输入是32个数字(输入图片中左下角位置32个通道中的数字),即相同高度和宽度上某一切片上的32个数字,这32个数字具有不同通道,乘以32个权重(将过滤器中的32个数理解为权重),然后应用ReLU非线性函数,在这里输出相应的结果。
一般来说,如果过滤器不止一个,而是多个,就好像有多个输入单元,其输入内容为一个切片上所有数字,输出结果是6×6过滤器数量。
所以1×1卷积可以从根本上理解为对这32个不同的位置都应用一个全连接层,全连接层的作用是输入32个数字(过滤器数量标记为\(n_{C}^{[l+1]}\),在这36个单元上重复此过程),输出结果是6×6×#filters(过滤器数量),以便在输入层上实施一个非平凡(non-trivial)计算。
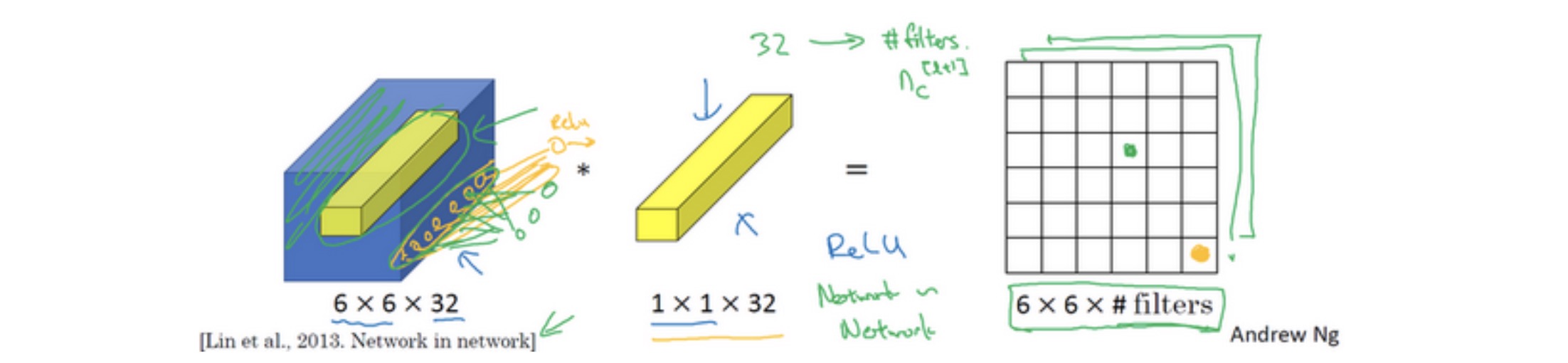
应用:压缩通道数
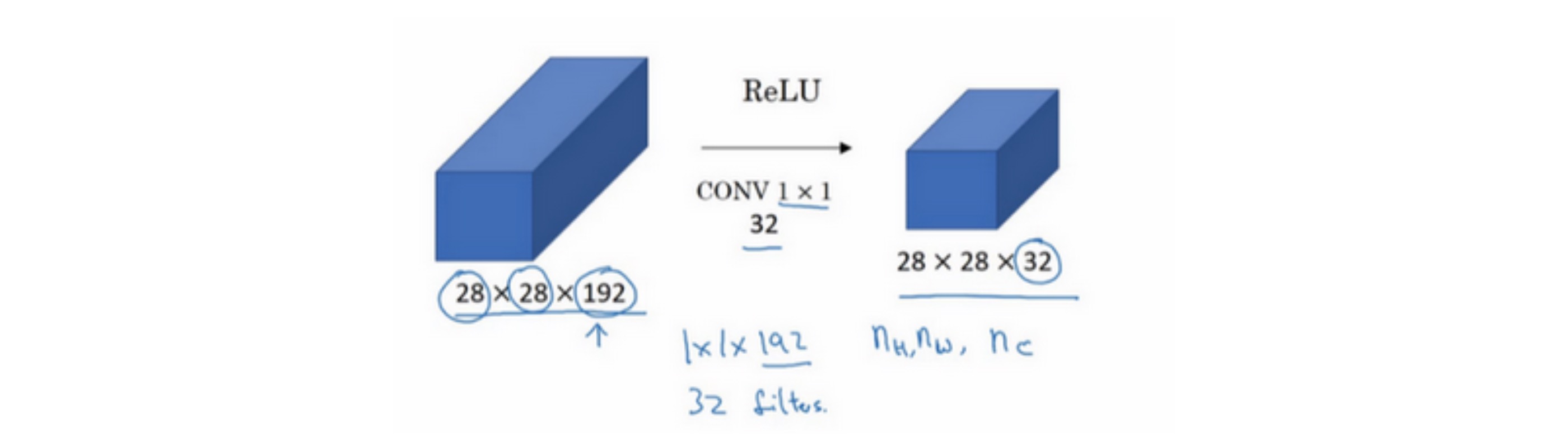
假设有一个28×28×192的输入层,你可以使用池化层压缩它的高度和宽度。但如果通道数量很大,该如何把它压缩为28×28×32维度的层呢?
可以用32个大小是1×1×192维的过滤器,因为过滤器中通道数量必须与输入层中通道的数量保持一致。使用了32个过滤器,输出层为28×28×32,就可以压缩通道数,对于池化层我只是压缩了这些层的高度和宽度。
1×1卷积层就是这样实现了一些重要功能的(doing something pretty non-trivial),它给神经网络添加了一个非线性函数,从而减少或保持输入层中的通道数量不变,也可以增加通道数量。这对构建Inception网络很有帮助。
Inception
Inception的思想
构建卷积层时,你要决定过滤器的大小究竟是1×1,3×3还是5×5,或者要不要添加池化层。Inception网络的作用就是代替你来决定。
基本思想是Inception网络不需要人为决定使用哪个过滤器或者是否需要池化,而是由网络自行确定这些参数,你可以给网络添加这些参数的所有可能值,然后把这些输出连接起来,让网络自己学习它需要什么样的参数,采用哪些过滤器组合。

这就是一个inception的模块,融合了不同卷积核的操作在输出。
瓶颈层
Inception这样的操作会导致计算成本过大。
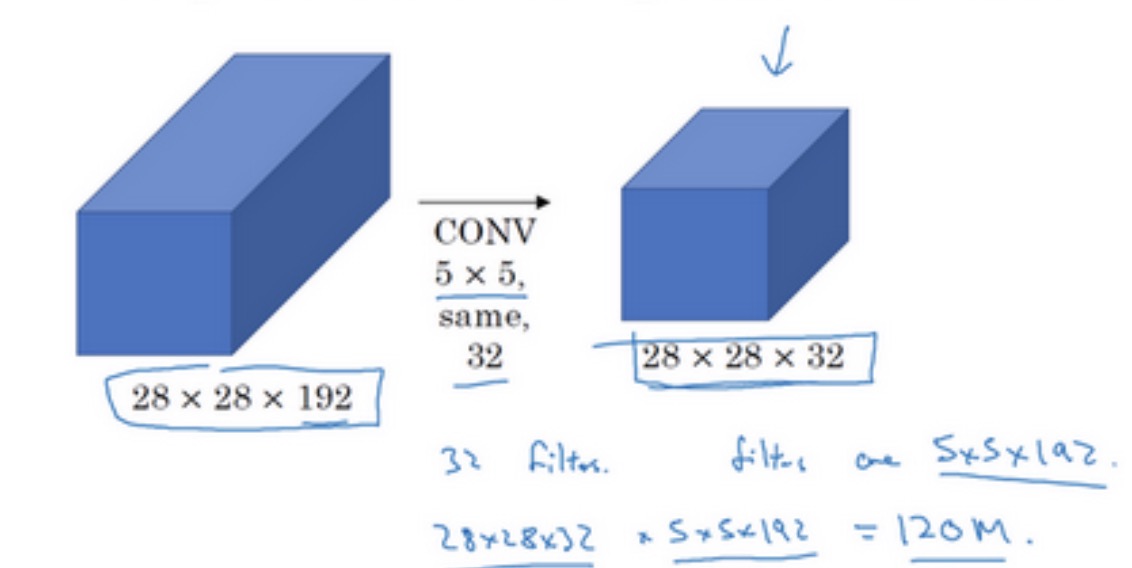
如上图所示,乘法运算的总次数为每个输出值所需要执行的乘法运算次数(5×5×192)乘以输出值个数(28×28×32),把这些数相乘结果等于1.2亿(120422400)。即使在现在,用计算机执行1.2亿次乘法运算,成本也是相当高的。
构建瓶颈层减少参数
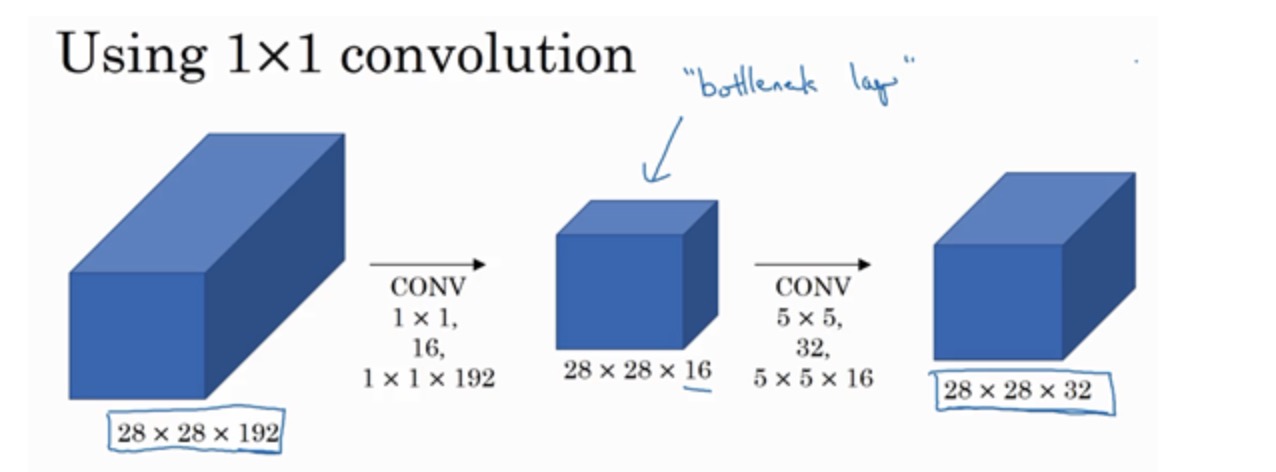
计算成本:
1、应用1×1卷积,过滤器个数为16,每个过滤器大小为1×1×192,这两个维度相匹配(输入通道数与过滤器通道数),28×28×16这个层的计算成本是,输出28×28×192中每个元素都做192次乘法,用1×1×192来表示,相乘结果约等于240万。(28×28×16×192)
2、第二个卷积层,28×28×32,对每个输出值应用一个5×5×16维度的过滤器,计算结果为1000万。
一共是1204万,将计算参数降低为十分之一。
构建Inception模块
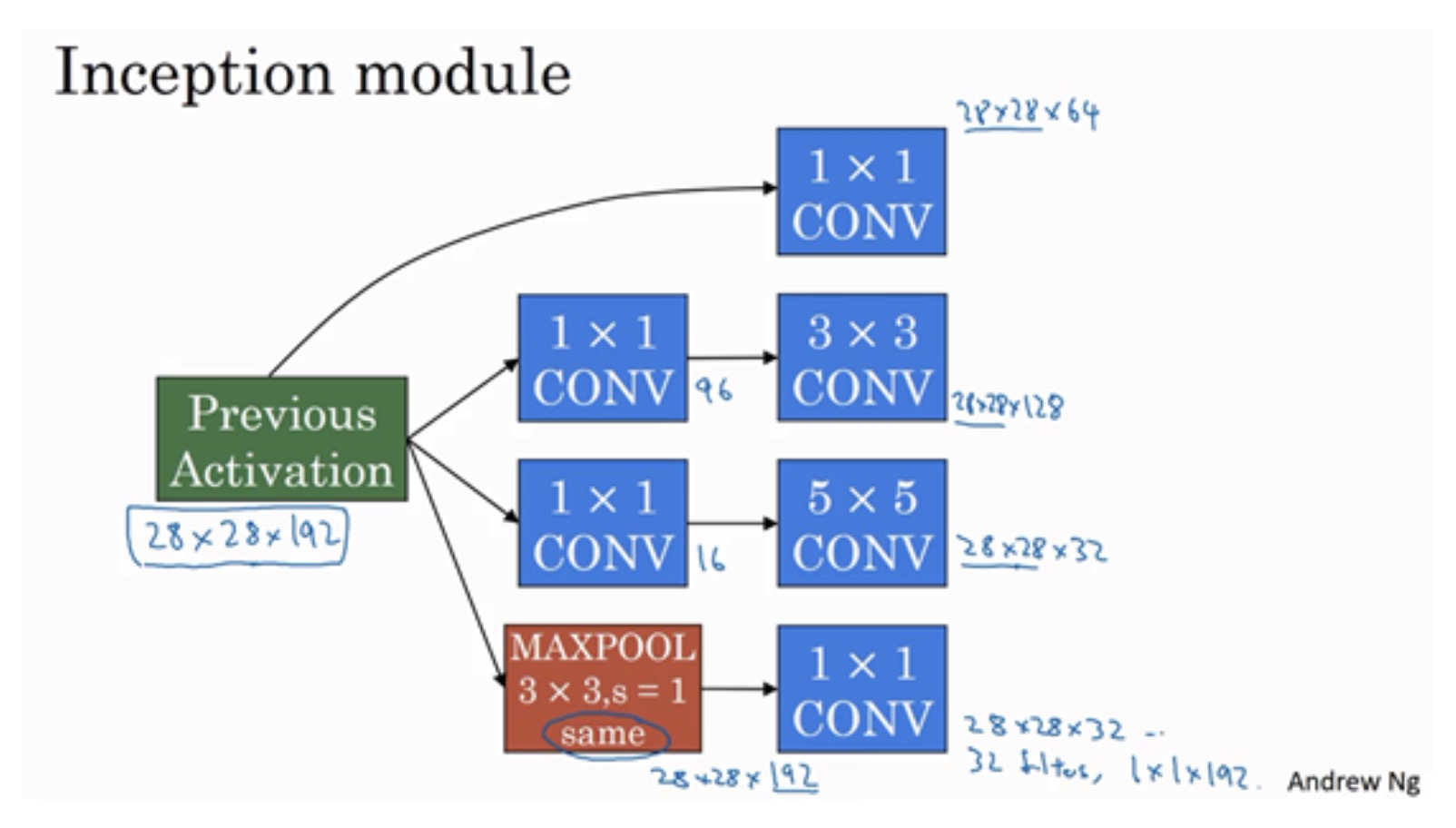
1、1×1的卷积层不用做操作
2、3×3的卷积层,先通过一个1×1的卷积做瓶颈层
3、5×5的卷积层,先通过一个1×1的卷积做瓶颈层
4、最大池化做same padding,然后用1×1的卷积将通道做降维
接下来阅读inception的论文,从v1到v4。