「Paper Read」YOLOV1
Abstract
1、 提出一个端到端的神经网络把目标检测看作一个回归问题来处理
2、YOLO提升了速度,产生了更多的定位误差,但是对背景的识别较好
Introduction
1、compare dpm 准确度不够
2、compare rcnn 速度跟不上
3、yolo把目标检测看作单一的回归问题,直接从图像像素到边界框和类概率

- yolo快
- yolo看到的是全局信息,比fast-rcnn检测背景精准度高一半
- yolo的泛化能力高
Unified Detection
Our network uses features from the entire image to predict each bounding box.
模型提取的是全局的信息,支持端到端的训练和实时的速度同时保持较高的平均精度。
Divide grid
首先会把原始图片resize到448×448,放缩到这个尺寸是为了后面整除来的方便。再把整个图片分成S×S(例:7×7)个单元格,此后以每个单元格为单位进行预测分析。
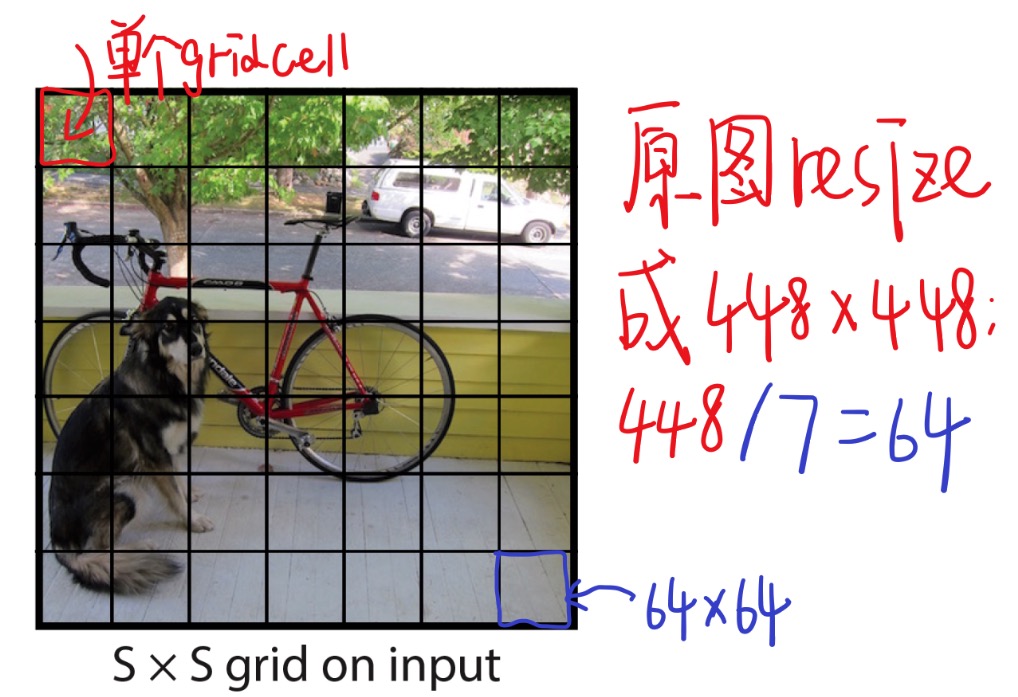
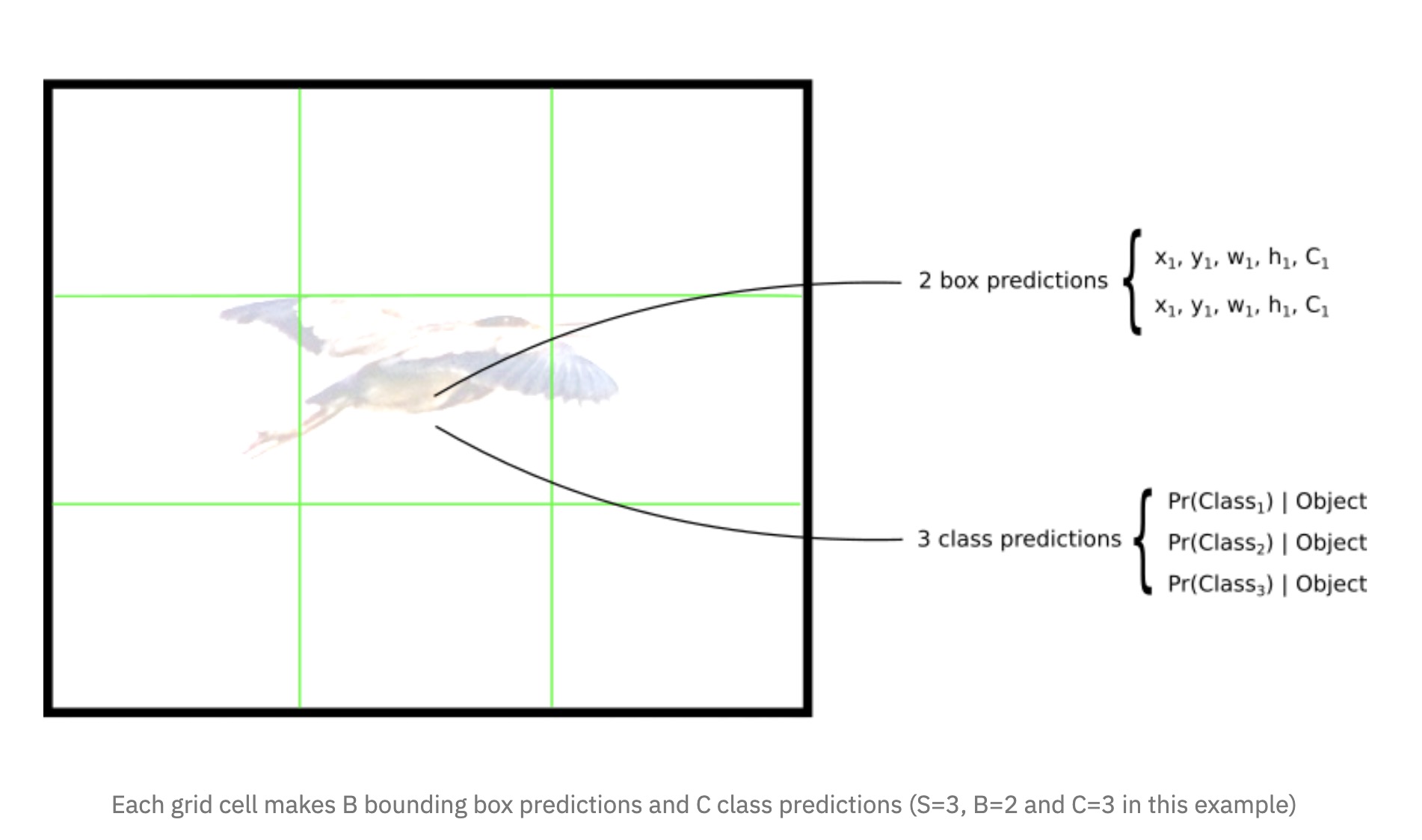
每个单元格需要做三件事
-
如果一个object的中心落在某个单元格上,那么这个单元格负责预测这个物体(论文的思想是让每个单元格单独干活)。
-
每个单元格需要预测B个bbox值(bbox值包括坐标和宽高),同时为每个bbox值预测一个置信度(confidence scores)。也就是每个单元格需要预测B×(4+1)个值。
-
每个单元格需要预测C(物体种类个数)个条件概率值.
单元格数据
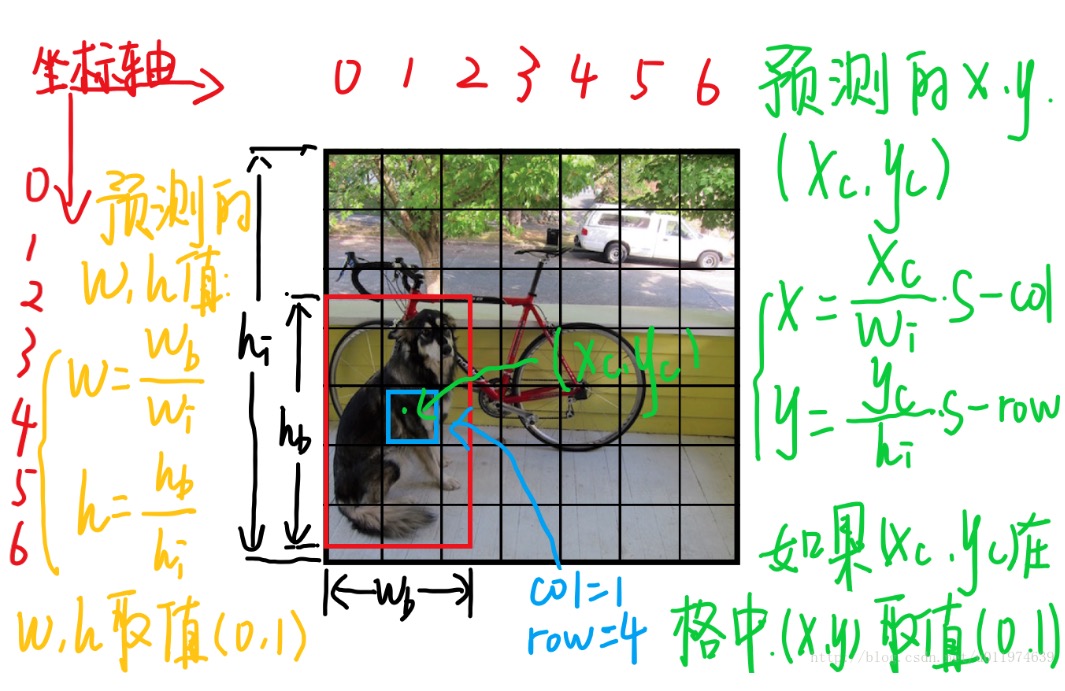
如上图,图片分成S×S(7×7)个单元格。整张图片的长宽为\(h_i\),\(w_i\)。
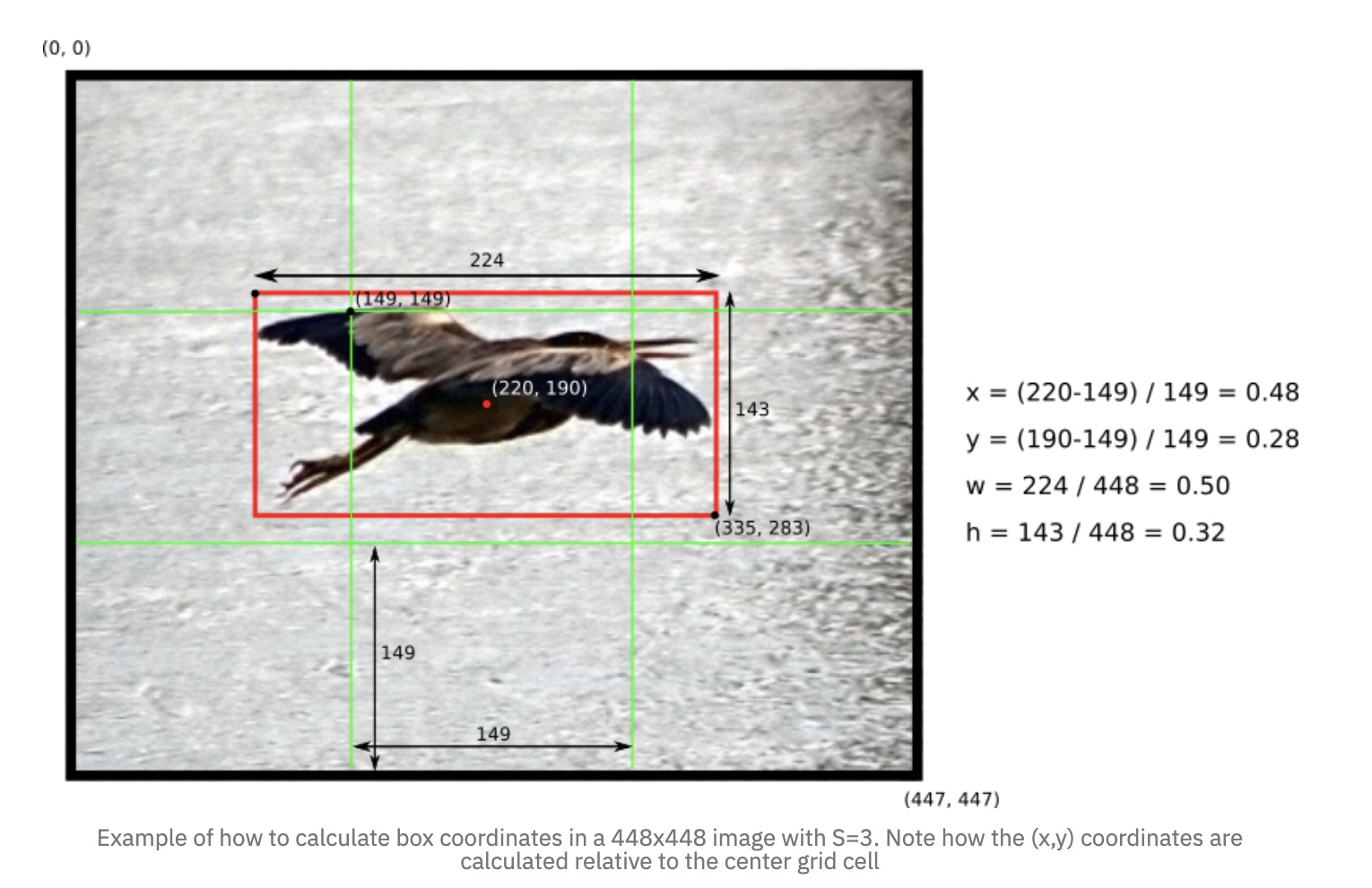
- (x,y)表示的是什么?

- (w,h)表示的是什么?



这就是每个单元格的class-specific confidence scores,这即包含了预测的类别信息,也包含了对bbox值的准确度。 我们可以设置一个阈值,把低分的class-specific confidence scores滤掉,剩下的塞给非极大值抑制,得到最终的标定框。 对于这部分可以看deepsystem.ai的PPT,讲的很详细,需要翻墙。
单元格的输出

所有单元格输出为7×7×(2×5+20,即最终的输出为7×7×30的张量。
YOLO检测物体流程
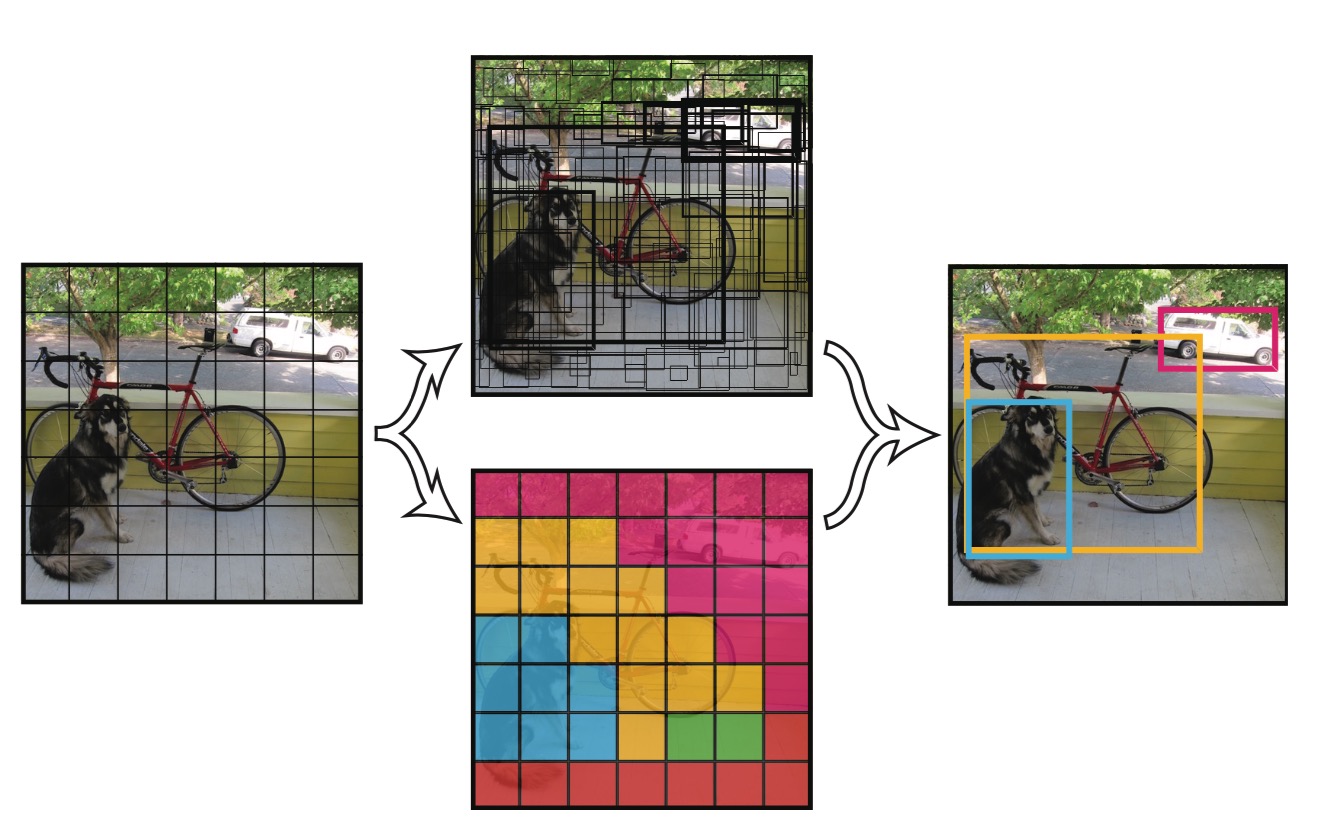
- 分割成单元格
- 预测bbox与类别信息,得到最终的specificconfidencespecificconfidence
- 设置阈值,滤掉低分的bbox
- 非极大值抑制得到最终的bbox
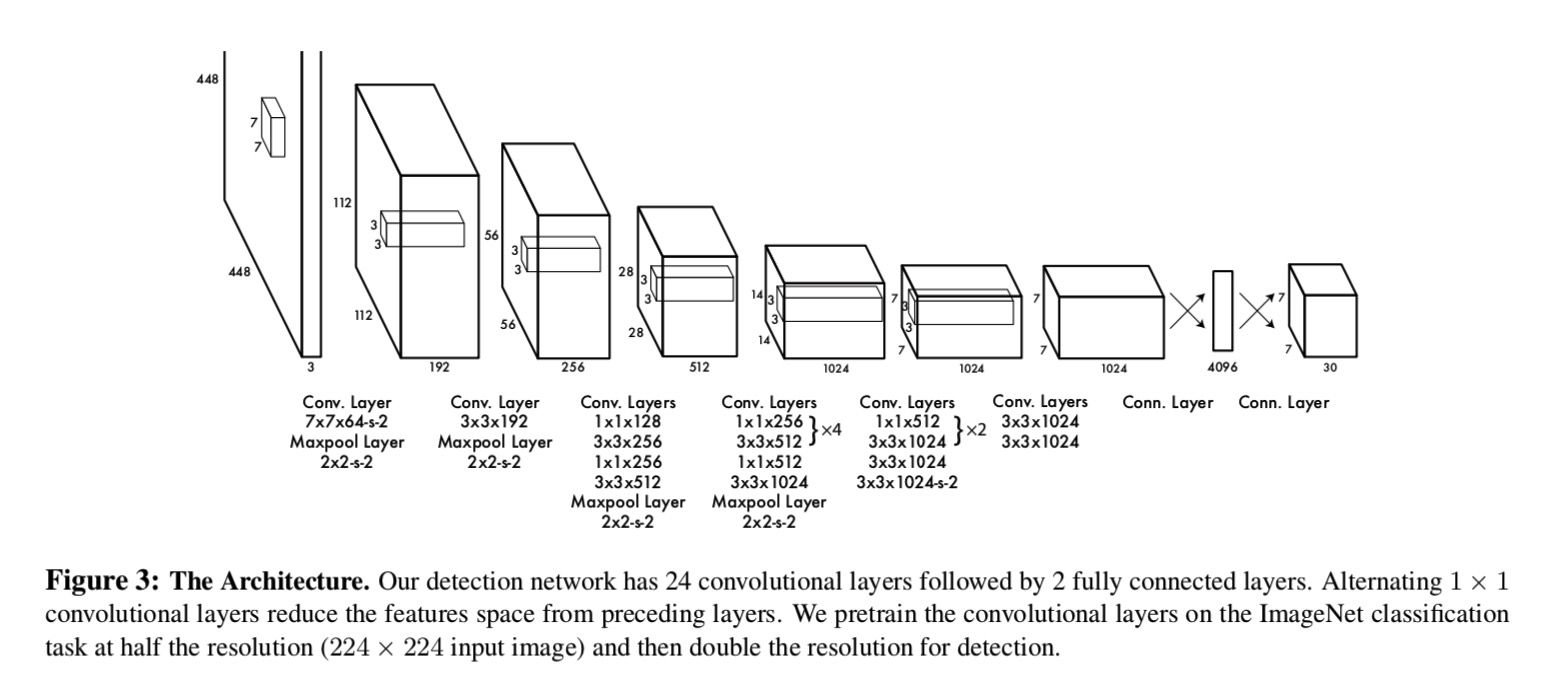
YOLO网络结构
┌────────────┬────────────────────────┬───────────────────┐
│ Name │ Filters │ Output Dimension │
├────────────┼────────────────────────┼───────────────────┤
│ Conv 1 │ 7 x 7 x 64, stride=2 │ 224 x 224 x 64 │
│ Max Pool 1 │ 2 x 2, stride=2 │ 112 x 112 x 64 │
│ Conv 2 │ 3 x 3 x 192 │ 112 x 112 x 192 │
│ Max Pool 2 │ 2 x 2, stride=2 │ 56 x 56 x 192 │
│ Conv 3 │ 1 x 1 x 128 │ 56 x 56 x 128 │
│ Conv 4 │ 3 x 3 x 256 │ 56 x 56 x 256 │
│ Conv 5 │ 1 x 1 x 256 │ 56 x 56 x 256 │
│ Conv 6 │ 1 x 1 x 512 │ 56 x 56 x 512 │
│ Max Pool 3 │ 2 x 2, stride=2 │ 28 x 28 x 512 │
│ Conv 7 │ 1 x 1 x 256 │ 28 x 28 x 256 │
│ Conv 8 │ 3 x 3 x 512 │ 28 x 28 x 512 │
│ Conv 9 │ 1 x 1 x 256 │ 28 x 28 x 256 │
│ Conv 10 │ 3 x 3 x 512 │ 28 x 28 x 512 │
│ Conv 11 │ 1 x 1 x 256 │ 28 x 28 x 256 │
│ Conv 12 │ 3 x 3 x 512 │ 28 x 28 x 512 │
│ Conv 13 │ 1 x 1 x 256 │ 28 x 28 x 256 │
│ Conv 14 │ 3 x 3 x 512 │ 28 x 28 x 512 │
│ Conv 15 │ 1 x 1 x 512 │ 28 x 28 x 512 │
│ Conv 16 │ 3 x 3 x 1024 │ 28 x 28 x 1024 │
│ Max Pool 4 │ 2 x 2, stride=2 │ 14 x 14 x 1024 │
│ Conv 17 │ 1 x 1 x 512 │ 14 x 14 x 512 │
│ Conv 18 │ 3 x 3 x 1024 │ 14 x 14 x 1024 │
│ Conv 19 │ 1 x 1 x 512 │ 14 x 14 x 512 │
│ Conv 20 │ 3 x 3 x 1024 │ 14 x 14 x 1024 │
│ Conv 21 │ 3 x 3 x 1024 │ 14 x 14 x 1024 │
│ Conv 22 │ 3 x 3 x 1024, stride=2 │ 7 x 7 x 1024 │
│ Conv 23 │ 3 x 3 x 1024 │ 7 x 7 x 1024 │
│ Conv 24 │ 3 x 3 x 1024 │ 7 x 7 x 1024 │
│ FC 1 │ - │ 4096 │
│ FC 2 │ - │ 7 x 7 x 30 (1470) │
└────────────┴────────────────────────┴───────────────────┘
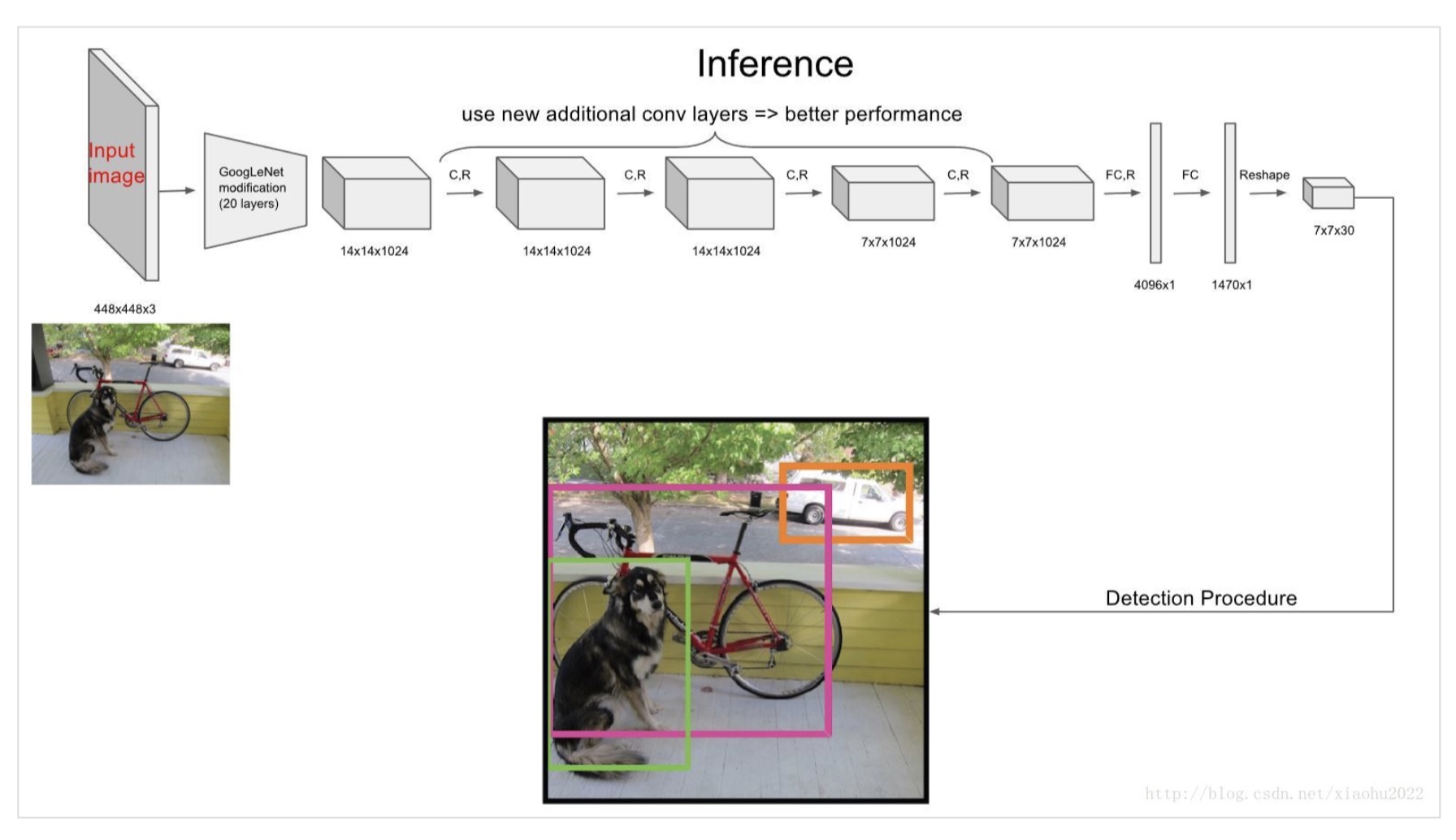
但是,在最新版的github版本中,可以看到最后两个全连接层被更改为:
[local]
size=3
stride=1
pad=1
filters=256
activation=leaky
[dropout]
probability=.5
[connected]
output= 1715
activation=linear
local是用的Locally Connected Layers结构,这种结构跟1x1卷积方式不同,1x1卷积核是利用很多个1x1大小的卷积核遍历整个特征图,而Locally Connected Layers结构则是一个介于全连接和卷积网络之间的一个结构:
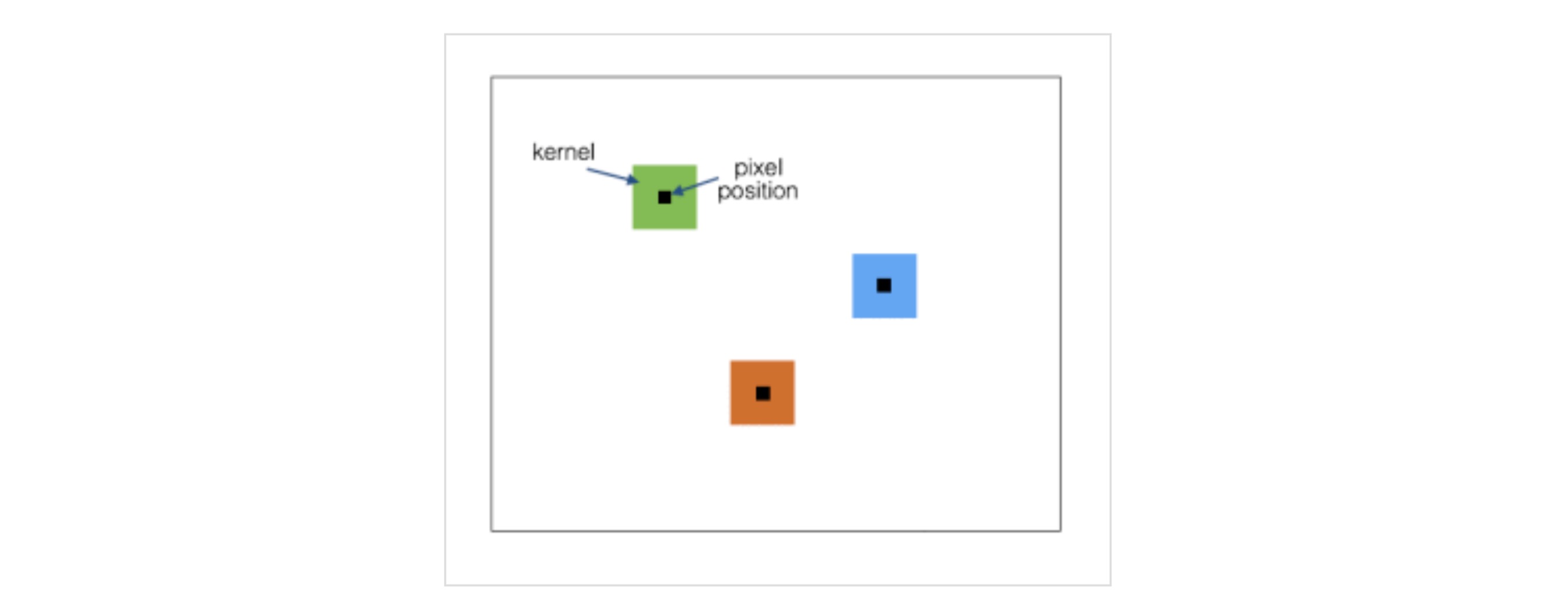
可以看到,它也是利用卷积的方式进行计算的,不同的地方在于随着卷积的不断遍历,每个遍历位置的卷积核都不一样,即没有了卷积层所特有的共享内存。其好处在于更多的利用了空间相对区域特征以及整体特征,从而提升了一点效果。
在不同位置学到不同的特征。
预训练
使用上图的前20个卷积层+平均池化+FC层在ImageNet上跑了一圈。(在ImageNet上跑是用的224×224224×224输入)。
预训练完事后,也就是get到了想要的前20个卷积层权重,在此基础上添加4个卷积层和2个FC层,得到最终模型(也就是上一个模块介绍的网络模型)。同时将网络的输入尺寸从224×224改成了448×448。
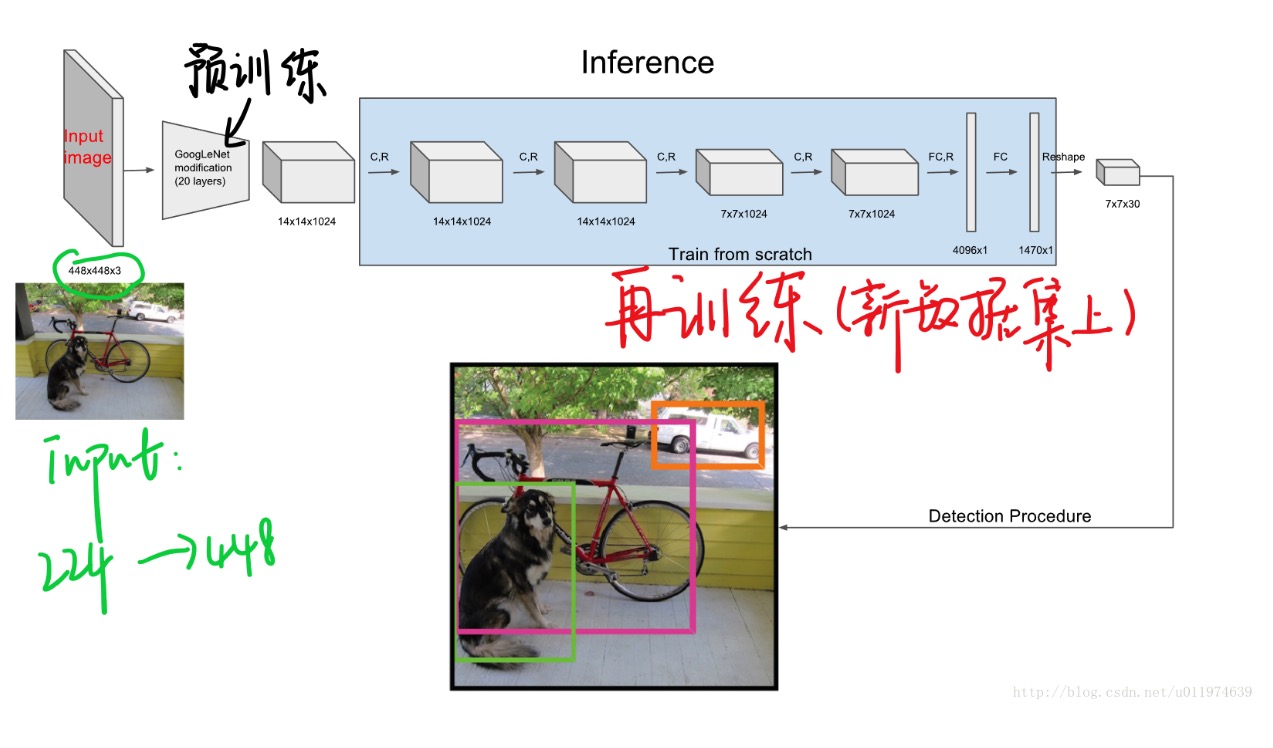
YOLO训练过程
前向传播
-
网络模型如前面的介绍所示。
-
激活函数采用的是leaky relu。
- \[\phi(x)=\left\{\begin{array}{ll}{x,} & {\text { if } x>0} \\ {0.1 x,} & {\text { otherwise }}\end{array}\right.\]
-
采用dropout。
- 采用BN。

损失函数
损失函数分为3个部分,每个部分都使用均方误差,利于求导。
但是如果用平方和误差,它将定位误差和分类误差同等对待是不太合理的,而且图像中有很多网格不包含任何物体,将这些网格的置信度趋向于0时的梯度将会超过含有物体的网格的梯度,会导致网络的不稳定,导致梯度爆炸。
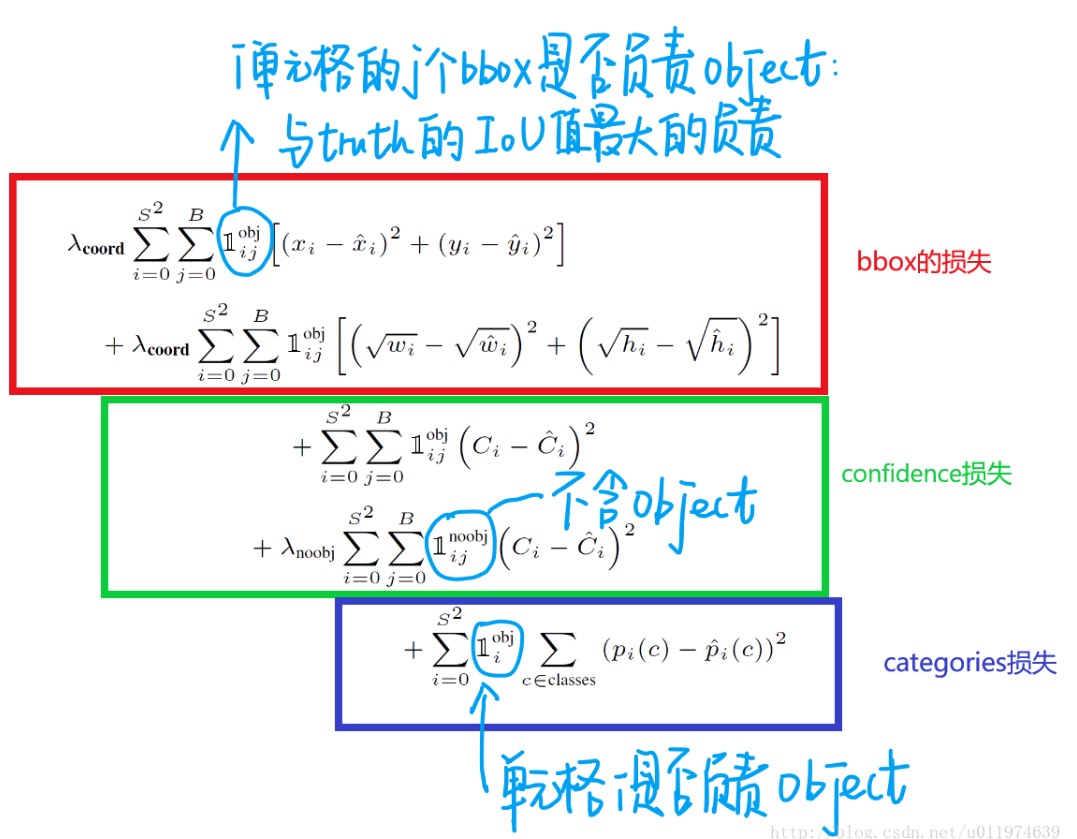
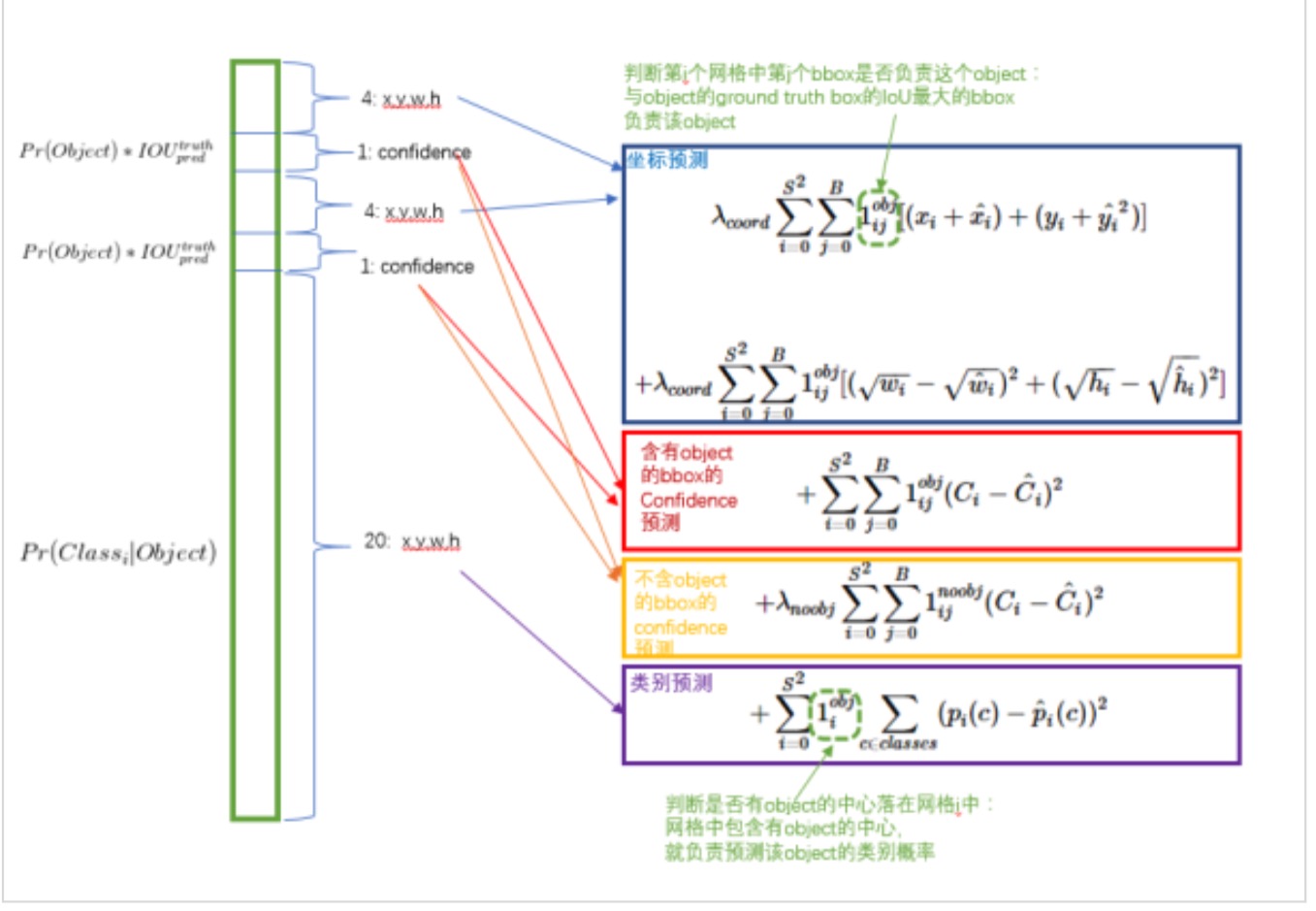
损失函数整体分为定位误差和分类误差(图中的中心位置x,y部分有错误),其中
(1)第一部分表示当区域内存在目标,且也检测到了匹配目标的前提下,计算目标框中心的均方误差,定位权重为5;
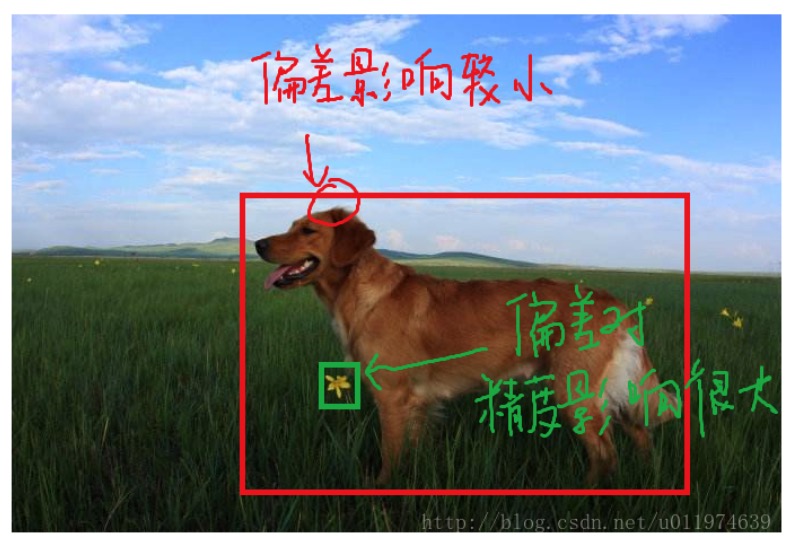
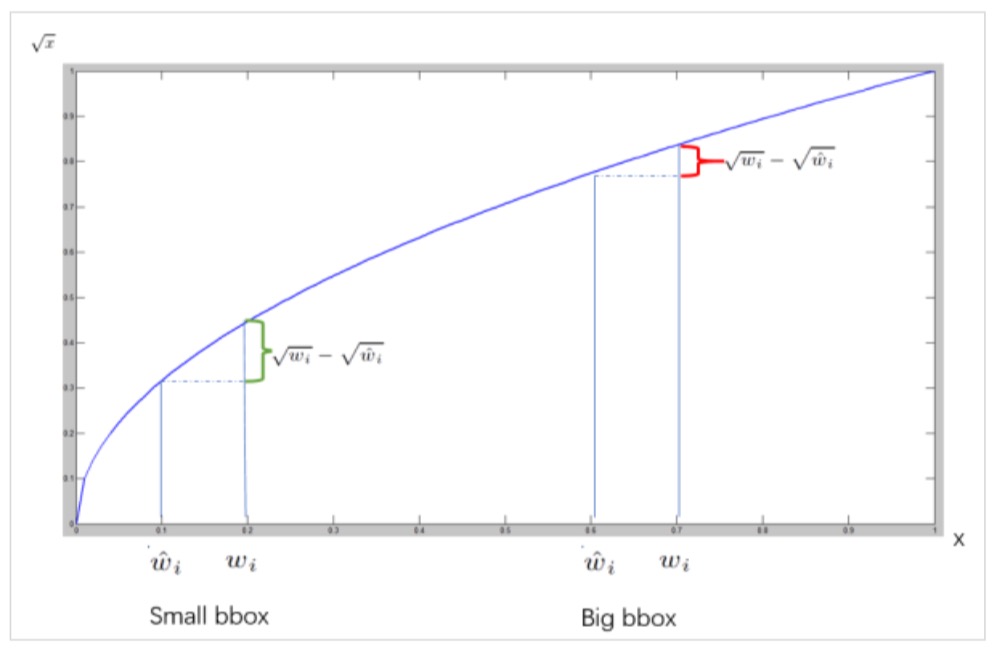
(2)第二部分就是当区域内存在目标,且也检测到了匹配目标的前提下,计算的目标框宽高的均方误差,定位权重为5,实际上作者训练的时候输出的就是宽高开平方后的结果。这里注意用宽和高的开根号代替原来的宽和高,这样做主要是因为相同的宽和高误差对于小的目标精度影响比大的目标要大。举个例子,原来 w=10,h=20,预测出来 w=8,h=22,跟原来 w=3,h=5,预测出来其实前者的误差要比后者下,但是如果不加开根号,那么损失都是一样:4+4=8,但是加上根号后,变成 0.15和 0.7;
(3)第三部分是分别计算当区域内真实目标和与之匹配的预测目标同时存在和不同时存在的情况下,边框置信度的均方误差,其中\(\widehat{C}_{i}\)表示的是真实目标框与预测目标框的IOU值。然而,大部分边界框都没有物体,积少成多,造成loss的不平衡,所以同时存在状态下的分类权重为1,不同时存在状态下的分类权重为0.5;
(4)第四部分计算的是当该区域存在目标时,计算目标类别均方误差。对于每个格子而言,作者设计只能包含同种物体,所以不用考虑多个bbox的情况。若格子中包含物体,我们希望希望预测正确的类别的概率越接近于1越好,而错误类别的概率越接近于0越好。
其中对于预测目标和groundtruth的匹配,作者除了利用IOU进行匹配之外,对于无匹配对象的ground,则是取与其(x,y,w,h)均方误差最小的目标框作为匹配对象。
学习率
YOLOv1采用的是multistep变化方式,即在特定的迭代次数更新学习率,论文中的YOLOv1采用的是学习率逐渐衰减的方式,但有意思的是最新的YOLOv1中学习率变化过程不同于传统的逐渐衰减方式,而是类似于当前新兴的warmup/warmrestart变化方式。我们知道传统的训练模式下:
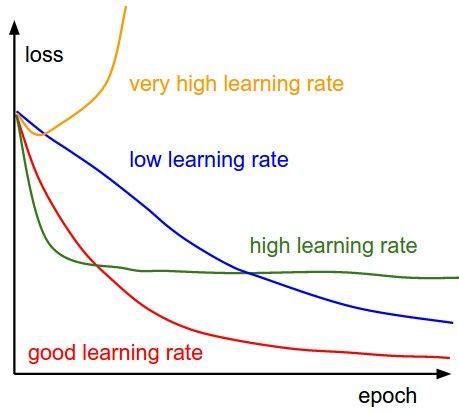
不断衰减的学习率可以稳定收敛,但是现在发现在某些模型训练过程中收敛效果并不好,所以就有研究者提出了“热重启”策略,当然也有类似的“循环”策略:
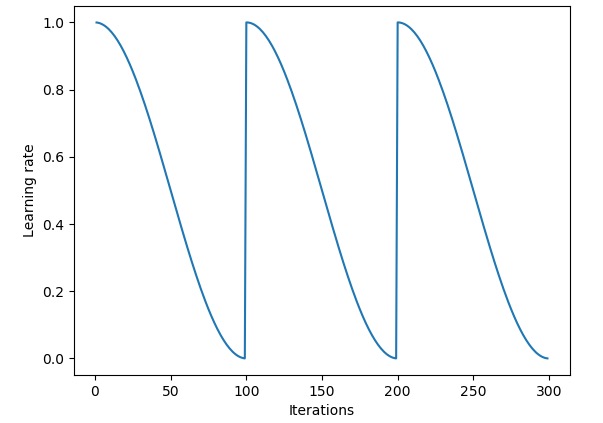
那么在YOLOv1中的学习率设定是:
复制
learning_rate=0.0005
policy=steps
steps=200,400,600,20000,30000
scales=2.5,2,2,.1,.1
可以看到,初始学习率只有0.0005,先慢慢增大,然后逐渐变小。
NMS
YOLO所采用的NMS算法流程如下:
- Step1 在网络输出结果之后,会得到7x7x2=98个目标框,首先会根据阈值将prob不合格(大概率属于背景)的目标框置信度置为0;
- Step2 对于每一个类别分开处理,先根据每个目标框在该类别下的prob置信度进行从大到小排序;
- Step3 对于排序好的第一个置信度不为0的目标框,依次计算与其他置信度不为0的目标框的IOU,如果IOU大于阈值,则将该目标框置信度置为0,且其对应的所有类别prob都置为0;
- Step4 转移至下一个置信度不为0的目标框,重复Step3,直到下一步没有置信度非0的目标框为止;
- Step5 重复Step2
- Step5 输出所有置信度非0的目标框,并根据阈值筛选有效目标。
yolov1中并没有用到softmax,所以可能同一个目标的多个类别的置信度都很高。
数据增强
作者在训练中主要采用了 jittering 和 HSV 空间扰动两种数据增强方式。
作者在 YOLO 和 YOLOv2 分别用了两种实现方法,第一种将 jittering 和 resize 分开了,采用双线性插值的方式,第二种则是将二者结合了,先在原图获取一定比例的亚像素值,然后再进行随机双线性插值,效果如下:

可以看到,方式一的 jittering 会将边界像素进行复制扩充,并且不会内部像素会进行重排,所以是各向异性 resize。而方式二就好像在保证原始图像比例的前提下,通过填充 0 像素达到规定尺寸,所以是各向同性 resize。然后随机将图像进行左右翻转,最后就是 HSV 空间扰动,具体原理还是直接看代码,由于每次随机的值都不一样,所以下面的图可能与上面的不是一致的:

测试效果
先放一张原论文中的实验效果图:
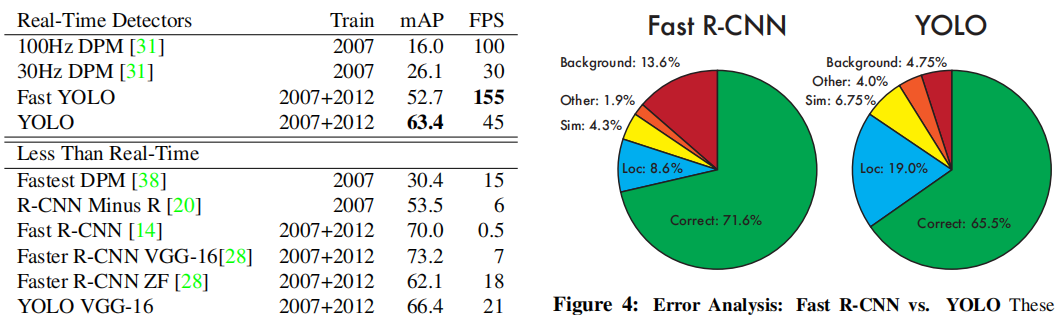
我们可以看到YOLOv1这个典型的one-stage目标检测算法,在速度大幅领先的前提下,只损失了7%的精度,并且值得注意的是YOLO相对于Fast RCNN将目标误识别为背景的概率小很多,所以作者做了一个小尝试,即以YOLO本身预测为主,逐个对比Fast RCNN和YOLO预测的目标框,根据置信度进行选择,也就是下面Fast R-CNN + YOLO的embedding组合。那么对于VOC各个类别的定位精度:
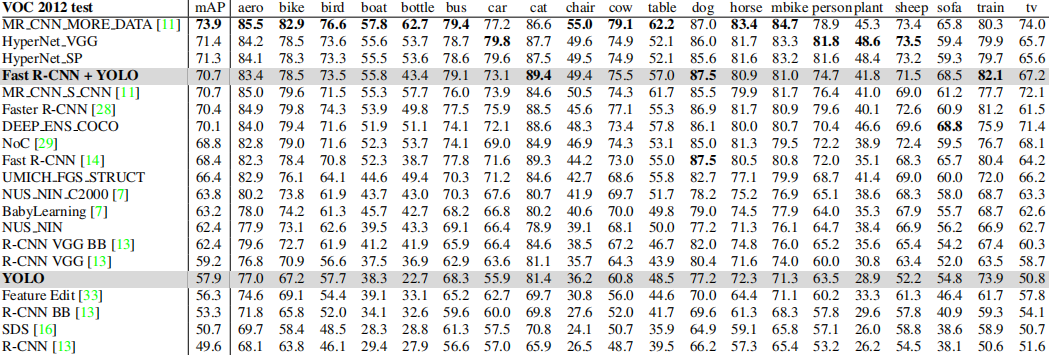
其对于稀疏大目标的定位效果还是能接受的:

优缺点
YOLO的优点不用多说,其作为当时最快的实时目标检测算法横空出世,SSD是在其后出来的,正式打开了one-stage目标检测算法的大门,虽然精度仍然不如Faster RCNN等,但是其速度很高,适合工程界研究改造。
当然其缺点也有很多:
- 1.YOLOv1采用了7x7的网格划分模式,每个网格只能预测两个同类别的目标框,那么就无法预测密集场景下的目标位置,如:拥挤人群;
- 2.YOLOv1的网格划分方式会影响每个目标的边界定位准确度,因为目标一般是跨网格区域的,如果目标只有一小部分在某个网格,那么可能就会被忽略;
- 3.NMS本身漏洞,NMS会将相邻的目标框去重,那么就会出现下面的情况:

另外,由于置信度和IOU并不是强相关的,那么对于下面的情况,则不得不选择更差的目标框:

- 4.固定分辨率,由于YOLOv1中存在全连接层,所以输入的分辨率必须固定,那么对于YOLOv1所固定的448x448大小分辨率,很多大分辨率图像中的目标会变得很小,另外许多非正方形分辨率的图像目标会失真。
参考资料
2、https://www.cnblogs.com/fariver/p/7446921.html
3、详解YOLO系列算法 五星推荐
4、https://medium.com/machine-learning-for-li/different-convolutional-layers-43dc146f4d0e