[TOC]
浅层神经网络
概念
神经网络的结构与逻辑回归类似,只是神经网络的层数比逻辑回归多一层,多出来的中间那层称为隐藏层或中间层。这样从计算上来说,神经网络的正向传播和反向传播过程只是比逻辑回归多了一次重复的计算。
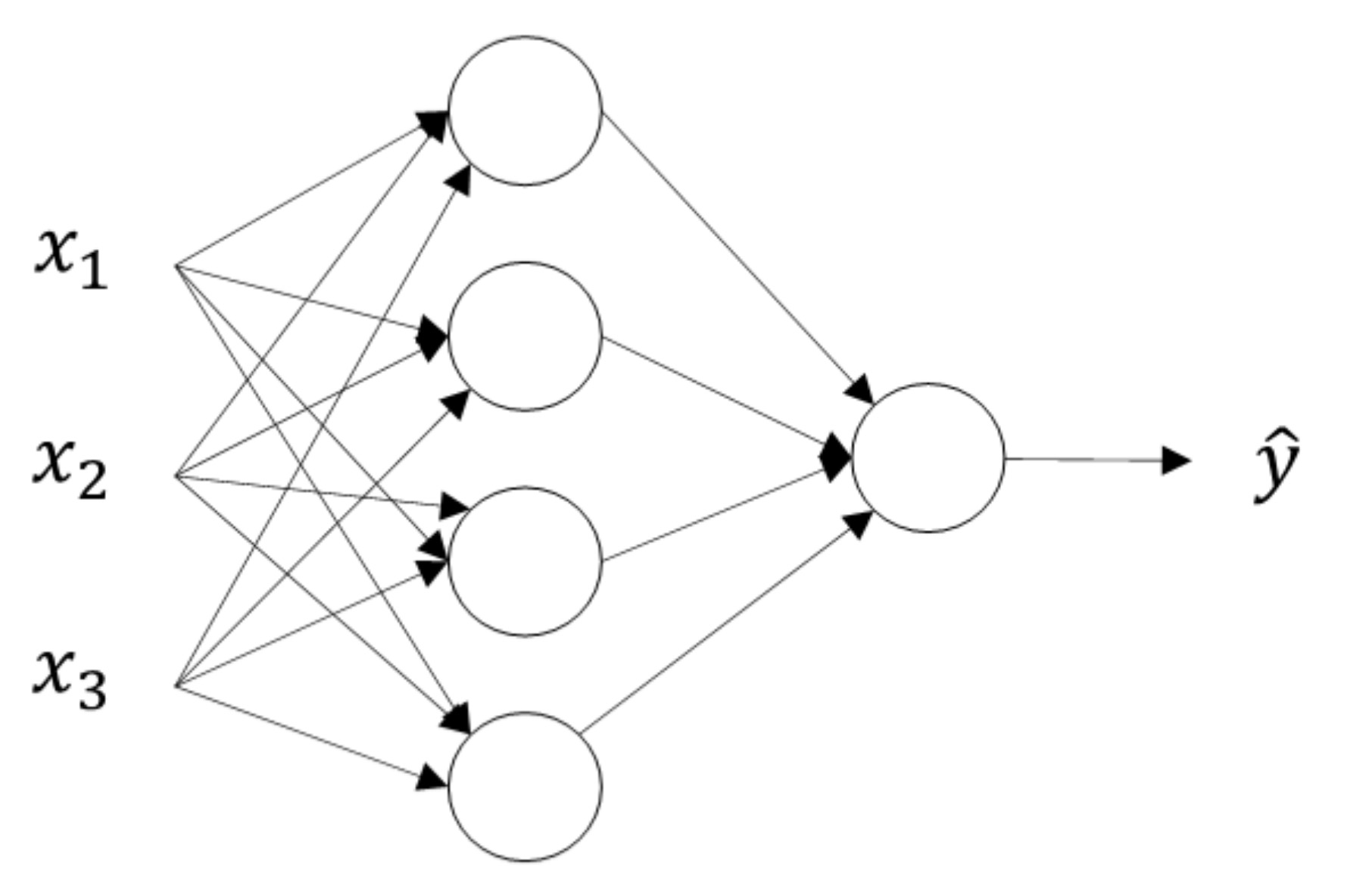
如上图所示:结构上,从左到右,可以分成三层:输入层(Input layer),隐藏层(Hidden layer)和输出层(Output layer)。输入层和输出层,对应着训练样本的输入和输出。隐藏层是抽象的非线性的中间层。
计算过程
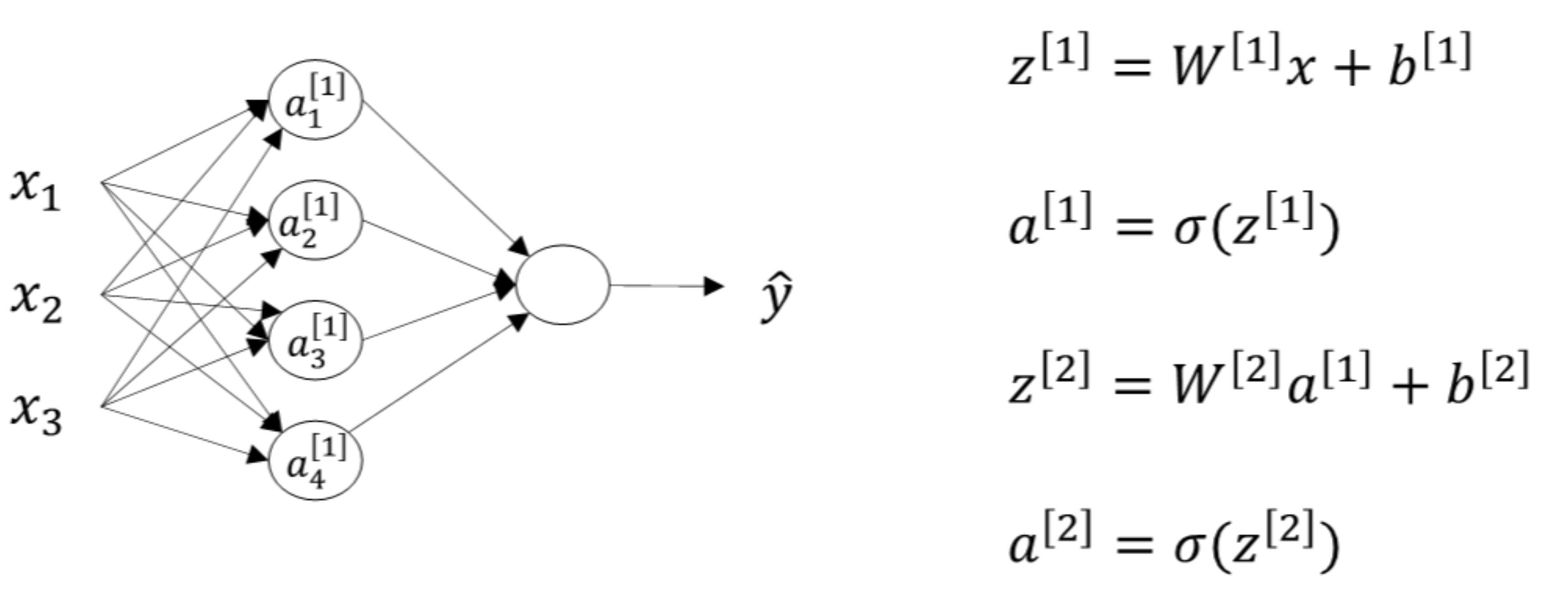
特别注意:* \(W^{[1]}\)的维度是(4,3),\(b^{[1]}\)的维度是(4,1),\(W^{[2]}\)的维度是(1,4),\(b^{[2]}\)的维度是(1,1)。
梯度计算

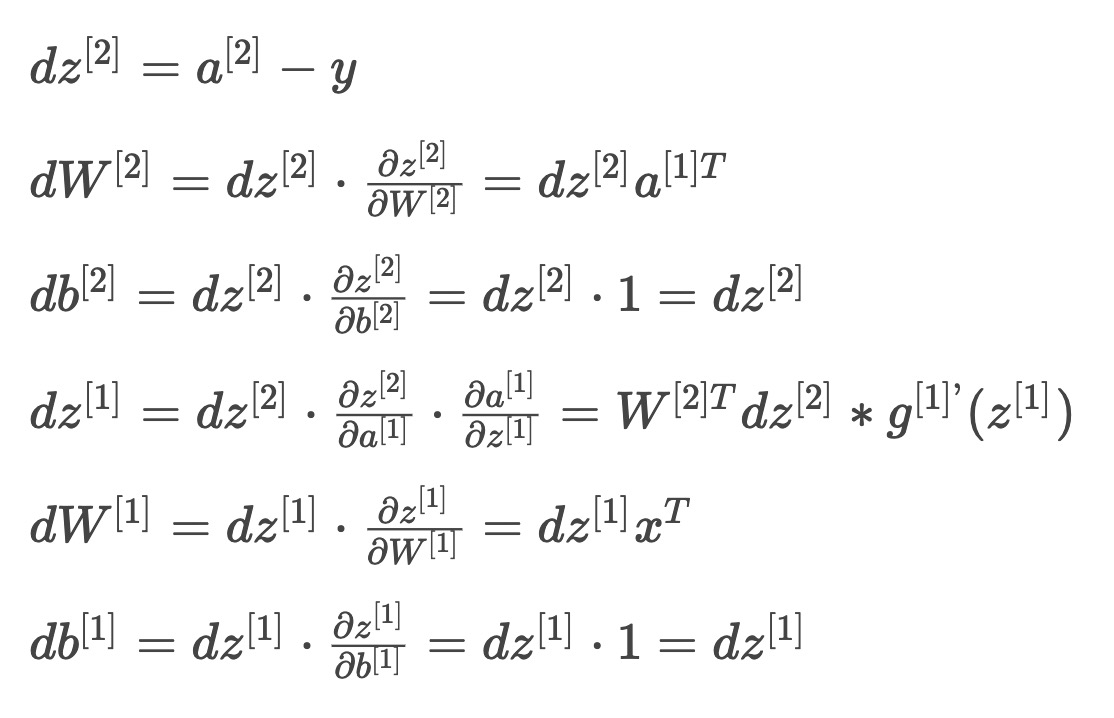
权重的初始化
逻辑回归的权重可以全部初始化为0,神经网络模型中的参数权重W不能全部初始化为0的。原因如下:
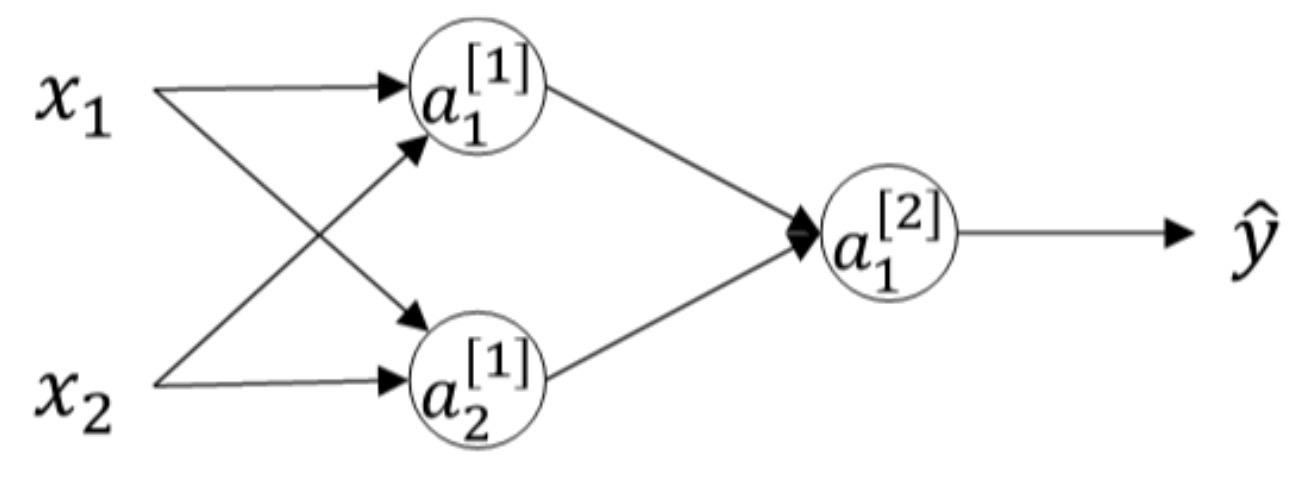
一个浅层神经网络包含两个输入,隐藏层包含两个神经元。如果全都初始化为零:
\[\begin{aligned} W^{[1]}=\left[\begin{array}{ll}{0} & {0} \\ {0} & {0}\end{array}\right] \quad \quad \quad W^{[2]} &=\left[\begin{array}{ll}{0} & {0}\end{array}\right] \end{aligned}\]这样使得隐藏层第一个神经元的输出等于第二个神经元的输出,即\(a_1^{[1]}=a_2^{[1]}\)。经过推导得到\(dz_1^{[1]}=dz_2^{[1]}\),以及\(dW_1^{[1]}=dW_2^{[1]}\)。因此,这样的结果是隐藏层两个神经元对应的权重行向量\(W_1^{[1]}\)和\(W_2^{[1]}\)每次迭代更新都会得到完全相同的结果,\(W_1^{[1]}\)始终等于\(W_2^{[1]}\),完全对称。这样隐藏层设置多个神经元就没有任何意义了。参数b可以全部初始化为零,不会影响神经网络训练效果。
当我们把所有的参数都设成0的话,那么上面的每一条边上的权重就都是0,那么神经网络就还是对称的,对于同一层的每个神经元,它们就一模一样了。
这样的后果是什么呢?我们知道,不管是哪个神经元,它的前向传播和反向传播的算法都是一样的,如果初始值也一样的话,不管训练多久,它们最终都一样,都无法打破对称(fail to break the symmetry),那每一层就相当于只有一个神经元,最终L层神经网络就相当于一个线性的网络,如Logistic regression,线性分类器对我们上面的非线性数据集是“无力”的,所以最终训练的结果就瞎猜一样。。
我们把这种权重W全部初始化为零带来的问题称为symmetry breaking problem。解决方法也很简单,就是将W进行随机初始化(b可初始化为零)。python里可以使用如下语句进行W和b的初始化:
W_1 = np.random.randn((2,2))*0.01
b_1 = np.zero((2,1))
W_2 = np.random.randn((1,2))*0.01
b_2 = 0
这里我们将\(W_1^{[1]}\)和\(W_2^{[1]}\)乘以0.01的目的是尽量使得权重W初始化比较小的值。之所以让W比较小,是因为如果使用sigmoid函数或者tanh函数作为激活函数的话,W比较小,得到的z也比较小(靠近零点),而零点区域的梯度比较大,这样能大大提高梯度下降算法的更新速度,尽快找到全局最优解。如果W较大,得到的z也比较大,附近曲线平缓,梯度较小,训练过程会慢很多。
当然,如果激活函数是ReLU或者Leaky ReLU函数,则不需要考虑这个问题。但是,如果输出层是sigmoid函数,则对应的权重W最好初始化到比较小的值。
代码
# -*- coding: utf-8 -*-
"""
本文博客地址:https://blog.csdn.net/u013733326/article/details/79702148
@author: Oscar
"""
import numpy as np
import matplotlib.pyplot as plt
from testCases import *
import sklearn
import sklearn.datasets
import sklearn.linear_model
from planar_utils import plot_decision_boundary, sigmoid, load_planar_dataset, load_extra_datasets
#%matplotlib inline #如果你使用用的是Jupyter Notebook的话请取消注释。
np.random.seed(1) #设置一个固定的随机种子,以保证接下来的步骤中我们的结果是一致的。
X, Y = load_planar_dataset()
#plt.scatter(X[0, :], X[1, :], c=Y, s=40, cmap=plt.cm.Spectral) #绘制散点图
shape_X = X.shape
shape_Y = Y.shape
m = Y.shape[1] # 训练集里面的数量
print ("X的维度为: " + str(shape_X))
print ("Y的维度为: " + str(shape_Y))
print ("数据集里面的数据有:" + str(m) + " 个")
def layer_sizes(X , Y):
"""
参数:
X - 输入数据集,维度为(输入的数量,训练/测试的数量)
Y - 标签,维度为(输出的数量,训练/测试数量)
返回:
n_x - 输入层的数量
n_h - 隐藏层的数量
n_y - 输出层的数量
"""
n_x = X.shape[0] #输入层
n_h = 4 #,隐藏层,硬编码为4
n_y = Y.shape[0] #输出层
return (n_x,n_h,n_y)
def initialize_parameters( n_x , n_h ,n_y):
"""
参数:
n_x - 输入节点的数量
n_h - 隐藏层节点的数量
n_y - 输出层节点的数量
返回:
parameters - 包含参数的字典:
W1 - 权重矩阵,维度为(n_h,n_x)
b1 - 偏向量,维度为(n_h,1)
W2 - 权重矩阵,维度为(n_y,n_h)
b2 - 偏向量,维度为(n_y,1)
"""
np.random.seed(2) #指定一个随机种子,以便你的输出与我们的一样。
W1 = np.random.randn(n_h,n_x) * 0.01
b1 = np.zeros(shape=(n_h, 1))
W2 = np.random.randn(n_y,n_h) * 0.01
b2 = np.zeros(shape=(n_y, 1))
#使用断言确保我的数据格式是正确的
assert(W1.shape == ( n_h , n_x ))
assert(b1.shape == ( n_h , 1 ))
assert(W2.shape == ( n_y , n_h ))
assert(b2.shape == ( n_y , 1 ))
parameters = {"W1" : W1,
"b1" : b1,
"W2" : W2,
"b2" : b2 }
return parameters
def forward_propagation( X , parameters ):
"""
参数:
X - 维度为(n_x,m)的输入数据。
parameters - 初始化函数(initialize_parameters)的输出
返回:
A2 - 使用sigmoid()函数计算的第二次激活后的数值
cache - 包含“Z1”,“A1”,“Z2”和“A2”的字典类型变量
"""
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
#前向传播计算A2
Z1 = np.dot(W1 , X) + b1
A1 = np.tanh(Z1)
Z2 = np.dot(W2 , A1) + b2
A2 = sigmoid(Z2)
#使用断言确保我的数据格式是正确的
assert(A2.shape == (1,X.shape[1]))
cache = {"Z1": Z1,
"A1": A1,
"Z2": Z2,
"A2": A2}
return (A2, cache)
def compute_cost(A2,Y,parameters):
"""
计算方程(6)中给出的交叉熵成本,
参数:
A2 - 使用sigmoid()函数计算的第二次激活后的数值
Y - "True"标签向量,维度为(1,数量)
parameters - 一个包含W1,B1,W2和B2的字典类型的变量
返回:
成本 - 交叉熵成本给出方程(13)
"""
m = Y.shape[1]
W1 = parameters["W1"]
W2 = parameters["W2"]
#计算成本
logprobs = logprobs = np.multiply(np.log(A2), Y) + np.multiply((1 - Y), np.log(1 - A2))
cost = - np.sum(logprobs) / m
cost = float(np.squeeze(cost))
assert(isinstance(cost,float))
return cost
def backward_propagation(parameters,cache,X,Y):
"""
使用上述说明搭建反向传播函数。
参数:
parameters - 包含我们的参数的一个字典类型的变量。
cache - 包含“Z1”,“A1”,“Z2”和“A2”的字典类型的变量。
X - 输入数据,维度为(2,数量)
Y - “True”标签,维度为(1,数量)
返回:
grads - 包含W和b的导数一个字典类型的变量。
"""
m = X.shape[1]
W1 = parameters["W1"]
W2 = parameters["W2"]
A1 = cache["A1"]
A2 = cache["A2"]
dZ2= A2 - Y
dW2 = (1 / m) * np.dot(dZ2, A1.T)
db2 = (1 / m) * np.sum(dZ2, axis=1, keepdims=True)
dZ1 = np.multiply(np.dot(W2.T, dZ2), 1 - np.power(A1, 2))
dW1 = (1 / m) * np.dot(dZ1, X.T)
db1 = (1 / m) * np.sum(dZ1, axis=1, keepdims=True)
grads = {"dW1": dW1,
"db1": db1,
"dW2": dW2,
"db2": db2 }
return grads
def update_parameters(parameters,grads,learning_rate=1.2):
"""
使用上面给出的梯度下降更新规则更新参数
参数:
parameters - 包含参数的字典类型的变量。
grads - 包含导数值的字典类型的变量。
learning_rate - 学习速率
返回:
parameters - 包含更新参数的字典类型的变量。
"""
W1,W2 = parameters["W1"],parameters["W2"]
b1,b2 = parameters["b1"],parameters["b2"]
dW1,dW2 = grads["dW1"],grads["dW2"]
db1,db2 = grads["db1"],grads["db2"]
W1 = W1 - learning_rate * dW1
b1 = b1 - learning_rate * db1
W2 = W2 - learning_rate * dW2
b2 = b2 - learning_rate * db2
parameters = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2}
return parameters
def nn_model(X,Y,n_h,num_iterations,print_cost=False):
"""
参数:
X - 数据集,维度为(2,示例数)
Y - 标签,维度为(1,示例数)
n_h - 隐藏层的数量
num_iterations - 梯度下降循环中的迭代次数
print_cost - 如果为True,则每1000次迭代打印一次成本数值
返回:
parameters - 模型学习的参数,它们可以用来进行预测。
"""
np.random.seed(3) #指定随机种子
n_x = layer_sizes(X, Y)[0]
n_y = layer_sizes(X, Y)[2]
parameters = initialize_parameters(n_x,n_h,n_y)
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
for i in range(num_iterations):
A2 , cache = forward_propagation(X,parameters)
cost = compute_cost(A2,Y,parameters)
grads = backward_propagation(parameters,cache,X,Y)
parameters = update_parameters(parameters,grads,learning_rate = 0.5)
if print_cost:
if i%1000 == 0:
print("第 ",i," 次循环,成本为:"+str(cost))
return parameters
def predict(parameters,X):
"""
使用学习的参数,为X中的每个示例预测一个类
参数:
parameters - 包含参数的字典类型的变量。
X - 输入数据(n_x,m)
返回
predictions - 我们模型预测的向量(红色:0 /蓝色:1)
"""
A2 , cache = forward_propagation(X,parameters)
predictions = np.round(A2)
return predictions
parameters = nn_model(X, Y, n_h = 4, num_iterations=10000, print_cost=True)
#绘制边界
plot_decision_boundary(lambda x: predict(parameters, x.T), X, Y)
plt.title("Decision Boundary for hidden layer size " + str(4))
predictions = predict(parameters, X)
print ('准确率: %d' % float((np.dot(Y, predictions.T) + np.dot(1 - Y, 1 - predictions.T)) / float(Y.size) * 100) + '%')
"""
plt.figure(figsize=(16, 32))
hidden_layer_sizes = [1, 2, 3, 4, 5, 20, 50] #隐藏层数量
for i, n_h in enumerate(hidden_layer_sizes):
plt.subplot(5, 2, i + 1)
plt.title('Hidden Layer of size %d' % n_h)
parameters = nn_model(X, Y, n_h, num_iterations=5000)
plot_decision_boundary(lambda x: predict(parameters, x.T), X, Y)
predictions = predict(parameters, X)
accuracy = float((np.dot(Y, predictions.T) + np.dot(1 - Y, 1 - predictions.T)) / float(Y.size) * 100)
print ("隐藏层的节点数量: {} ,准确率: {} %".format(n_h, accuracy))
"""
[1] https://www.jianshu.com/p/e817b2bcab63
[2] https://blog.csdn.net/u013733326/article/details/79702148
[3] https://redstonewill.com/955/